 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Query-by-Example Keyword Spotting with Metric Learning and Phoneme-to-Embedding Mapping
Paper and Code
Apr 19, 2023
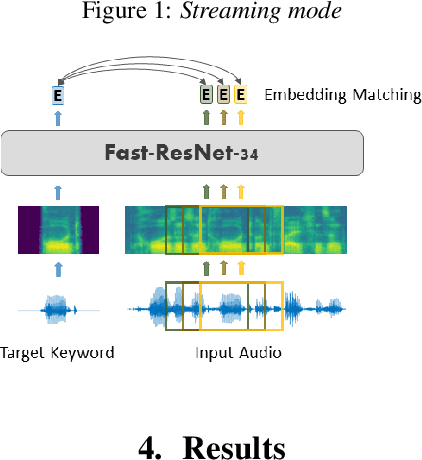

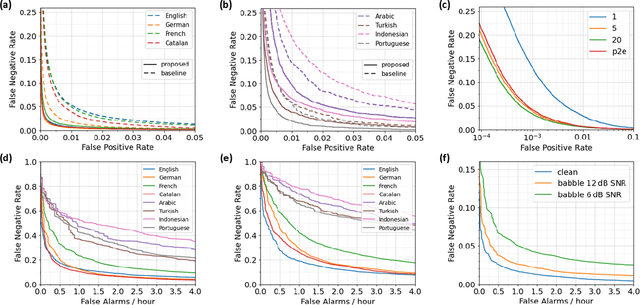
In this paper, we propose a multilingual query-by-example keyword spotting (KWS) system based on a residual neural network. The model is trained as a classifier on a multilingual keyword dataset extracted from Common Voice sentences and fine-tuned using circle loss. We demonstrate the generalization ability of the model to new languages and report a mean reduction in EER of 59.2 % for previously seen and 47.9 % for unseen languages compared to a competitive baseline. We show that the word embeddings learned by the KWS model can be accurately predicted from the phoneme sequences using a simple LSTM model. Our system achieves a promising accuracy for streaming keyword spotting and keyword search on Common Voice audio using just 5 examples per keyword. Experiments on the Hey-Snips dataset show a good performance with a false negative rate of 5.4 % at only 0.1 false alarms per hour.