Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Open Text 1.0: Public Domain News in 44 Languages
Paper and Code
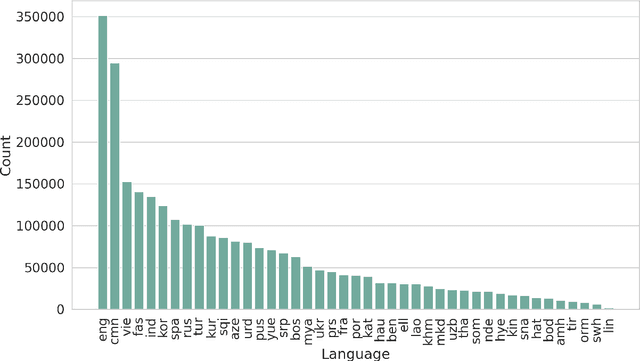
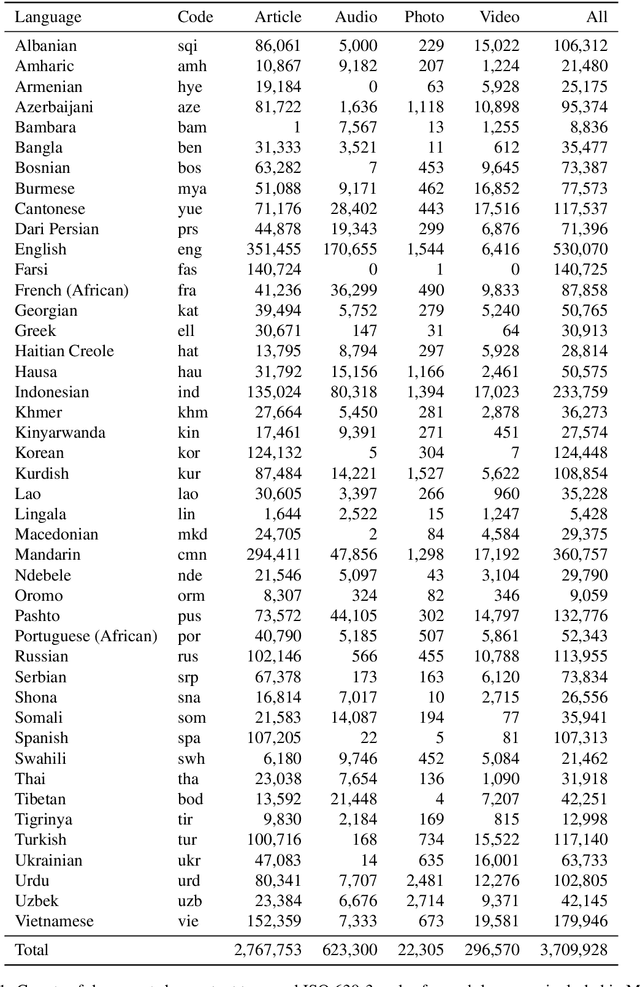
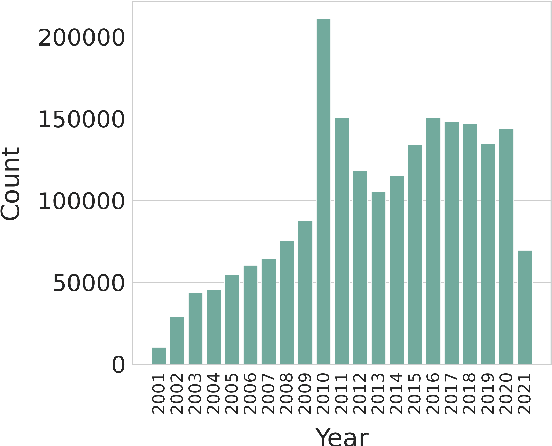

We present a new multilingual corpus containing text in 44 languages, many of which have relatively few existing resources for natural language processing. The first release of the corpus contains over 2.7 million news articles and 1 million shorter passages published between 2001--2021, collected from Voice of America news websites. We describe our process for collecting, filtering, and processing the data. The source material is in the public domain, our collection is licensed using a creative commons license (CC BY 4.0), and all software used to create the corpus is released under the MIT License. The corpus will be regularly updated as additional documents are published.
* Submitted to LREC 2022
View paper on