 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Gradient Word-Order Typology from Universal Dependencies
Paper and Code
Feb 02, 2024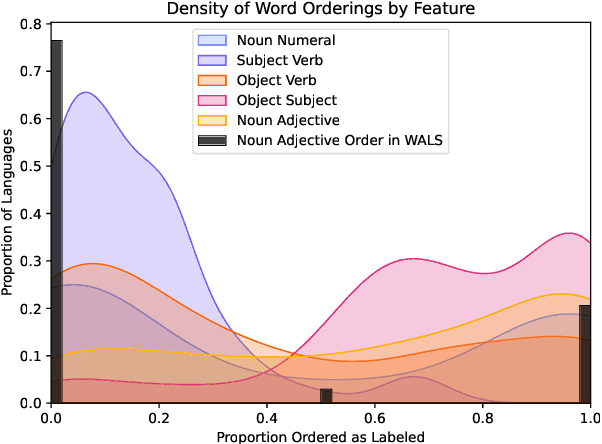



While information from the field of linguistic typology has the potential to improve performance on NLP tasks, reliable typological data is a prerequisite. Existing typological databases, including WALS and Grambank, suffer from inconsistencies primarily caused by their categorical format. Furthermore, typological categorisations by definition differ significantly from the continuous nature of phenomena, as found in natural language corpora. In this paper, we introduce a new seed dataset made up of continuous-valued data, rather than categorical data, that can better reflect the variability of language. While this initial dataset focuses on word-order typology, we also present the methodology used to create the dataset, which can be easily adapted to generate data for a broader set of features and languages.