 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilevel Sentence Embeddings for Personality Prediction
Paper and Code
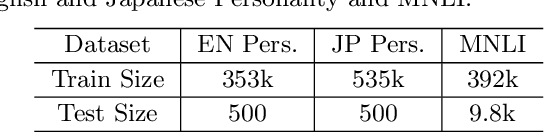


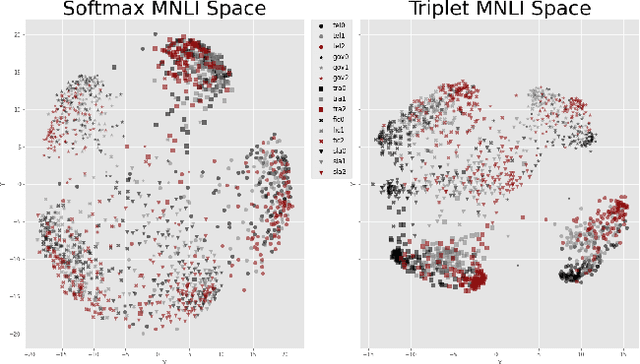
Representing text into a multidimensional space can be done with sentence embedding models such as Sentence-BERT (SBERT). However, training these models when the data has a complex multilevel structure requires individually trained class-specific models, which increases time and computing costs. We propose a two step approach which enables us to map sentences according to their hierarchical memberships and polarity. At first we teach the upper level sentence space through an AdaCos loss function and then finetune with a novel loss function mainly based on the cosine similarity of intra-level pairs. We apply this method to three different datasets: two weakly supervised Big Five personality dataset obtained from English and Japanese Twitter data and the benchmark MNLI dataset. We show that our single model approach performs better than multiple class-specific classification models.