 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Pre-Trained Model for Code Vulnerability Identification
Paper and Code
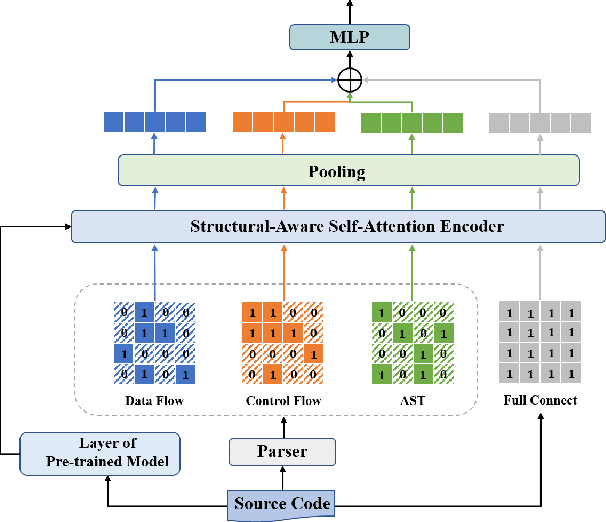
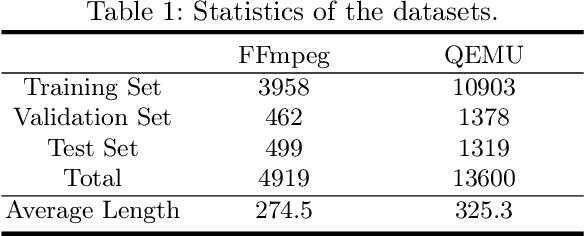
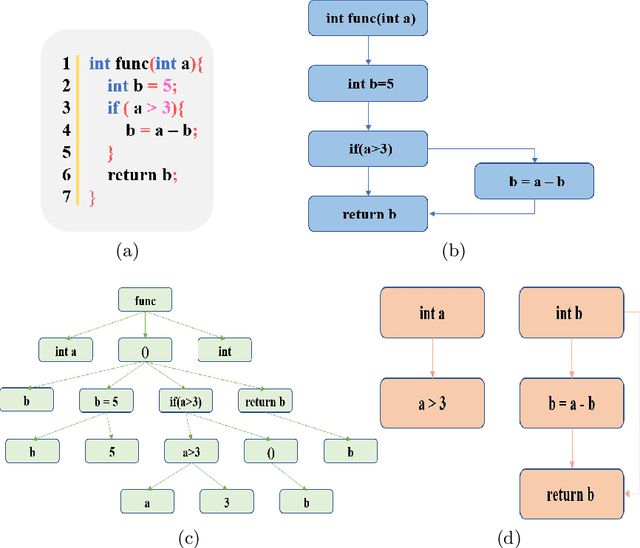

Vulnerability identification is crucial for cyber security in the software-related industry. Early identification methods require significant manual efforts in crafting features or annotating vulnerable code. Although the recent pre-trained models alleviate this issue, they overlook the multiple rich structural information contained in the code itself. In this paper, we propose a novel Multi-View Pre-Trained Model (MV-PTM) that encodes both sequential and multi-type structural information of the source code and uses contrastive learning to enhance code representations. The experiments conducted on two public datasets demonstrate the superiority of MV-PTM. In particular, MV-PTM improves GraphCodeBERT by 3.36\% on average in terms of F1 score.