 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Learning by a Top-Down Control Network
Paper and Code
Feb 23, 2020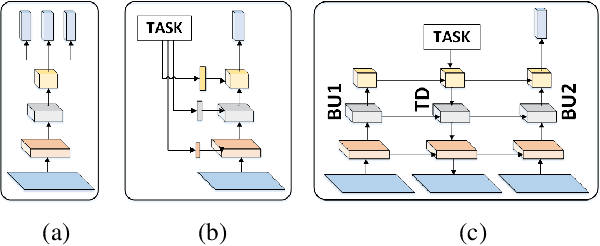
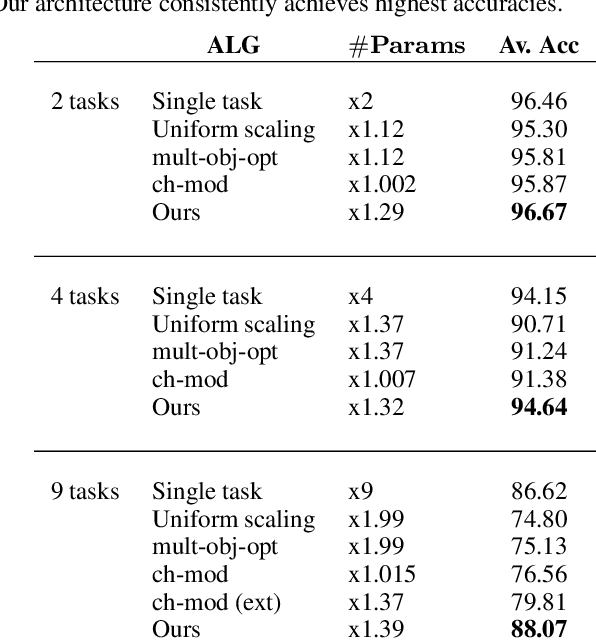


A general problem that received considerable recent attention is how to perform multiple tasks in the same network, maximizing both prediction accuracy and efficiency of training. Recent approaches address this problem by branching networks, or by a channel-wise modulation of the feature-maps with task specific vectors. We propose a novel architecture that uses a top-down network to modify the main network according to the task in a channel-wise, as well as spatial-wise, image-dependent computation scheme. We show the effectiveness of our scheme by achieving better results than alternative state-of-the-art approaches to multi-task learning. We also demonstrate our advantages in terms of task selectivity, scaling the number of tasks, learning from fewer examples and interpretability.