 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stream Keypoint Attention Network for Sign Language Recognition and Translation
Paper and Code
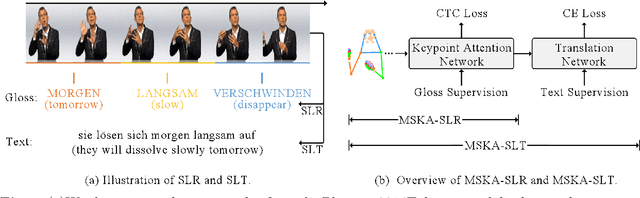



Sign language serves as a non-vocal means of communication, transmitting information and significance through gestures, facial expressions, and bodily movements. The majority of current approaches for sign language recognition (SLR) and translation rely on RGB video inputs, which are vulnerable to fluctuations in the background. Employing a keypoint-based strategy not only mitigates the effects of background alterations but also substantially diminishes the computational demands of the model. Nevertheless, contemporary keypoint-based methodologies fail to fully harness the implicit knowledge embedded in keypoint sequences. To tackle this challenge, our inspiration is derived from the human cognition mechanism, which discerns sign language by analyzing the interplay between gesture configurations and supplementary elements. We propose a multi-stream keypoint attention network to depict a sequence of keypoints produced by a readily available keypoint estimator. In order to facilitate interaction across multiple streams, we investigate diverse methodologies such as keypoint fusion strategies, head fusion, and self-distillation. The resulting framework is denoted as MSKA-SLR, which is expanded into a sign language translation (SLT) model through the straightforward addition of an extra translation network. We carry out comprehensive experiments on well-known benchmarks like Phoenix-2014, Phoenix-2014T, and CSL-Daily to showcase the efficacy of our methodology. Notably, we have attained a novel state-of-the-art performance in the sign language translation task of Phoenix-2014T. The code and models can be accessed at: https://github.com/sutwangyan/MSKA.