 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-stage Speaker Extraction with Utterance and Frame-Level Reference Signals
Paper and Code
Nov 19, 2020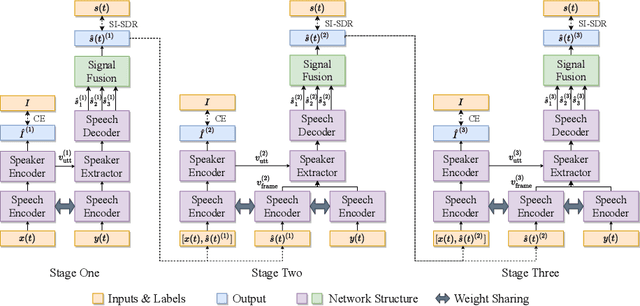
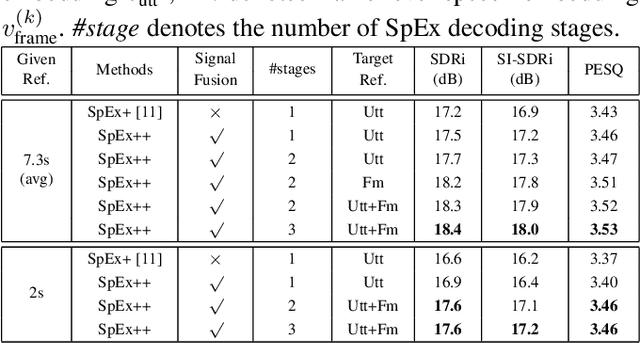

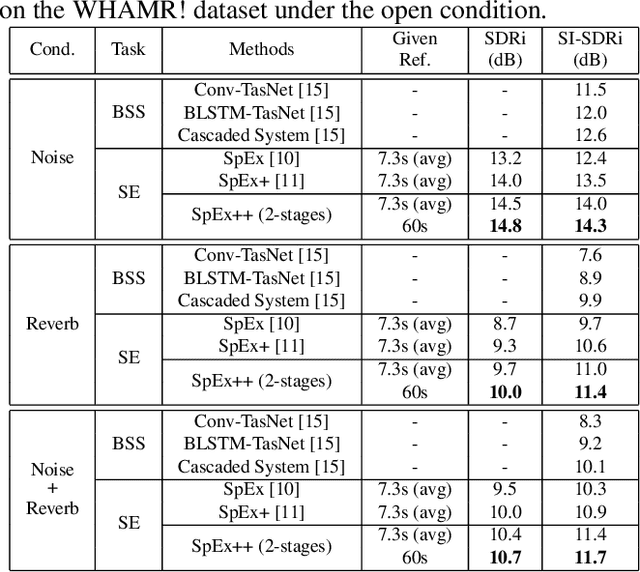
Speaker extraction uses a pre-recorded reference speech as the reference signal for target speaker extraction. In real-world applications, enrolling a speaker with a long speech is not practical. We propose a speaker extraction technique, that performs in multiple stages to take full advantage of short reference speech sample. The extracted speech in early stages is used as the reference speech for late stages. Furthermore, for the first time, we use frame-level sequential speech embedding as the reference for target speaker. This is a departure from the traditional utterance-based speaker embedding reference. In addition, a signal fusion scheme is proposed to combine the decoded signals in multiple scales with automatically learned weights. Experiments on WSJ0-2mix and its noisy versions (WHAM! and WHAMR!) show that SpEx++ consistently outperforms other state-of-the-art baselines.