 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Transformer Language Models
Paper and Code
May 01, 2020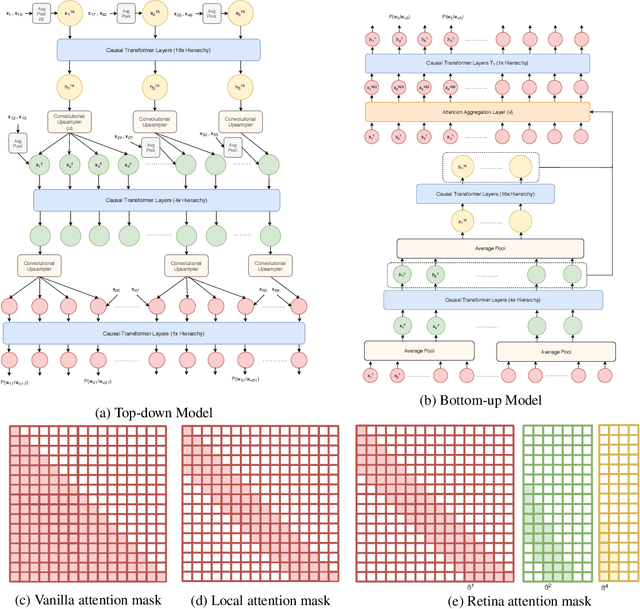
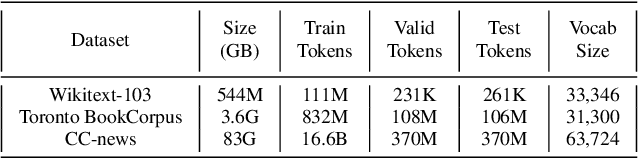
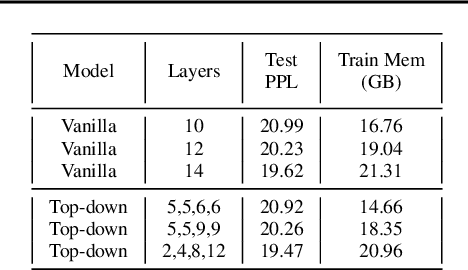

We investigate multi-scale transformer language models that learn representations of text at multiple scales, and present three different architectures that have an inductive bias to handle the hierarchical nature of language. Experiments on large-scale language modeling benchmarks empirically demonstrate favorable likelihood vs memory footprint trade-offs, e.g. we show that it is possible to train a hierarchical variant with 30 layers that has 23% smaller memory footprint and better perplexity, compared to a vanilla transformer with less than half the number of layers, on the Toronto BookCorpus. We analyze the advantages of learned representations at multiple scales in terms of memory footprint, compute time, and perplexity, which are particularly appealing given the quadratic scaling of transformers' run time and memory usage with respect to sequence length.