 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Person Absolute 3D Human Pose Estimation with Weak Depth Supervision
Paper and Code
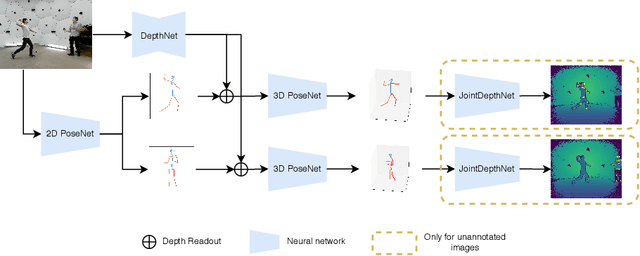



In 3D human pose estimation one of the biggest problems is the lack of large, diverse datasets. This is especially true for multi-person 3D pose estimation, where, to our knowledge, there are only machine generated annotations available for training. To mitigate this issue, we introduce a network that can be trained with additional RGB-D images in a weakly supervised fashion. Due to the existence of cheap sensors, videos with depth maps are widely available, and our method can exploit a large, unannotated dataset. Our algorithm is a monocular, multi-person, absolute pose estimator. We evaluate the algorithm on several benchmarks, showing a consistent improvement in error rates. Also, our model achieves state-of-the-art results on the MuPoTS-3D dataset by a considerable margin.