 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Optimization for Self-Adjusting Weighted Gradient in Machine Learning Tasks
Paper and Code
Jul 21, 2015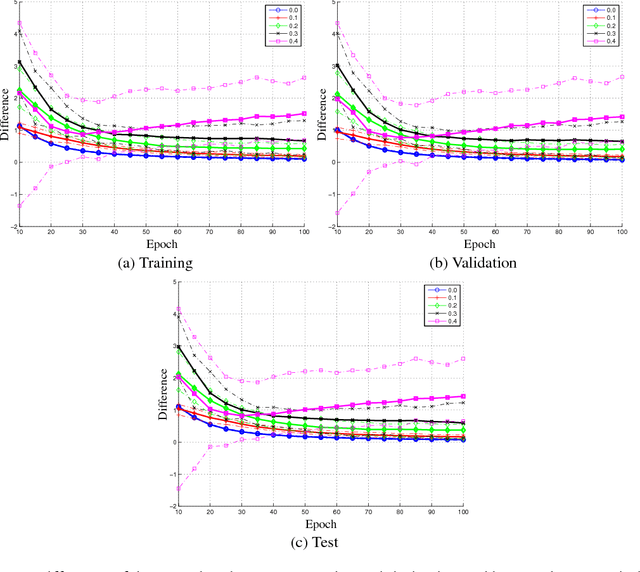
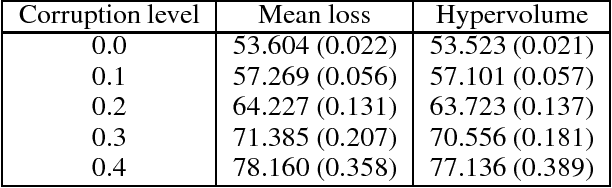
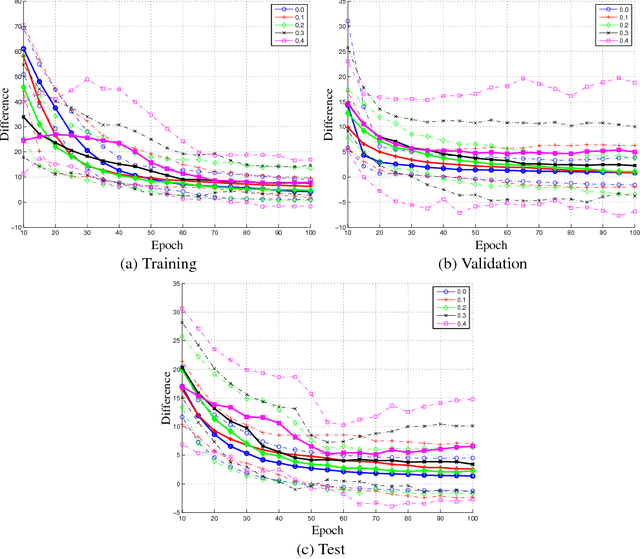
Much of the focus in machine learning research is placed in creating new architectures and optimization methods, but the overall loss function is seldom questioned. This paper interprets machine learning from a multi-objective optimization perspective, showing the limitations of the default linear combination of loss functions over a data set and introducing the hypervolume indicator as an alternative. It is shown that the gradient of the hypervolume is defined by a self-adjusting weighted mean of the individual loss gradients, making it similar to the gradient of a weighted mean loss but without requiring the weights to be defined a priori. This enables an inner boosting-like behavior, where the current model is used to automatically place higher weights on samples with higher losses but without requiring the use of multiple models. Results on a denoising autoencoder show that the new formulation is able to achieve better mean loss than the direct optimization of the mean loss, providing evidence to the conjecture that self-adjusting the weights creates a smoother loss surface.