 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Unsupervised Pre-Training for Surgical Operating Room Workflow Analysis
Paper and Code
Jul 16, 2022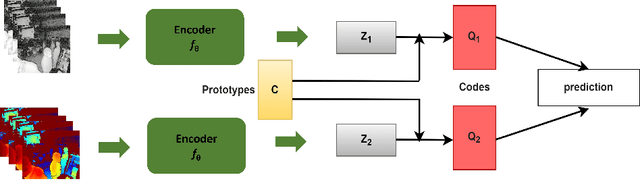
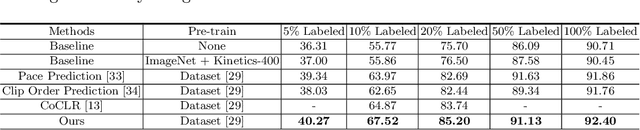
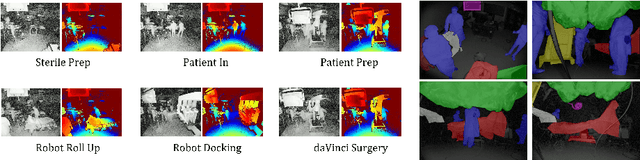

Data-driven approaches to assist operating room (OR) workflow analysis depend on large curated datasets that are time consuming and expensive to collect. On the other hand, we see a recent paradigm shift from supervised learning to self-supervised and/or unsupervised learning approaches that can learn representations from unlabeled datasets. In this paper, we leverage the unlabeled data captured in robotic surgery ORs and propose a novel way to fuse the multi-modal data for a single video frame or image. Instead of producing different augmentations (or 'views') of the same image or video frame which is a common practice in self-supervised learning, we treat the multi-modal data as different views to train the model in an unsupervised manner via clustering. We compared our method with other state of the art methods and results show the superior performance of our approach on surgical video activity recognition and semantic segmentation.