 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Lingual DALL-E Storytime
Paper and Code

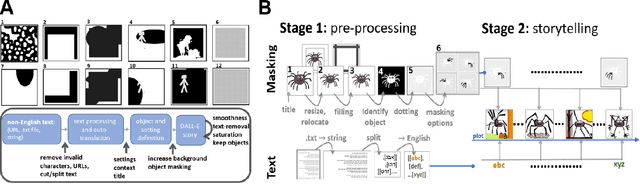
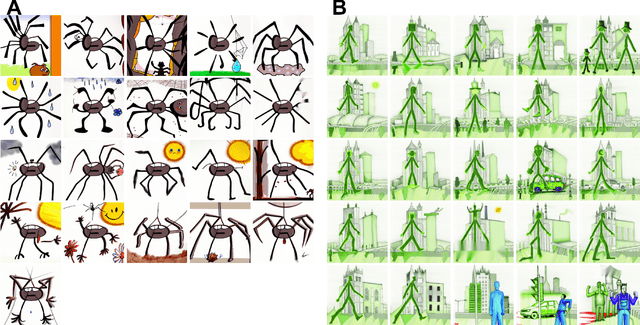

While recent advancements in artificial intelligence (AI) language models demonstrate cutting-edge performance when working with English texts, equivalent models do not exist in other languages or do not reach the same performance level. This undesired effect of AI advancements increases the gap between access to new technology from different populations across the world. This unsought bias mainly discriminates against individuals whose English skills are less developed, e.g., non-English speakers children. Following significant advancements in AI research in recent years, OpenAI has recently presented DALL-E: a powerful tool for creating images based on English text prompts. While DALL-E is a promising tool for many applications, its decreased performance when given input in a different language, limits its audience and deepens the gap between populations. An additional limitation of the current DALL-E model is that it only allows for the creation of a few images in response to a given input prompt, rather than a series of consecutive coherent frames that tell a story or describe a process that changes over time. Here, we present an easy-to-use automatic DALL-E storytelling framework that leverages the existing DALL-E model to enable fast and coherent visualizations of non-English songs and stories, pushing the limit of the one-step-at-a-time option DALL-E currently offers. We show that our framework is able to effectively visualize stories from non-English texts and portray the changes in the plot over time. It is also able to create a narrative and maintain interpretable changes in the description across frames. Additionally, our framework offers users the ability to specify constraints on the story elements, such as a specific location or context, and to maintain a consistent style throughout the visualization.