 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level Attention Fusion Network for Audio-visual Event Recognition
Paper and Code
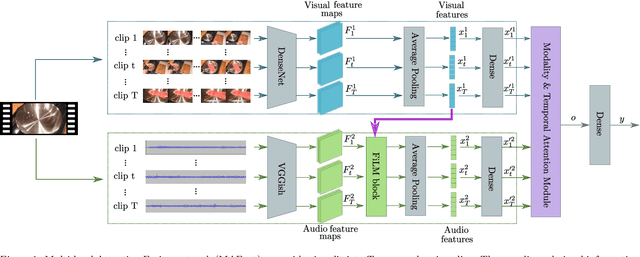
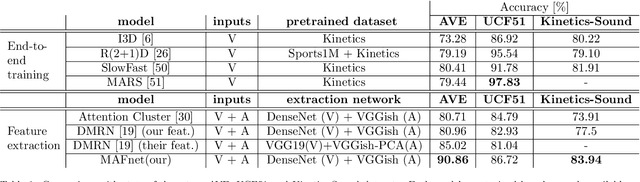
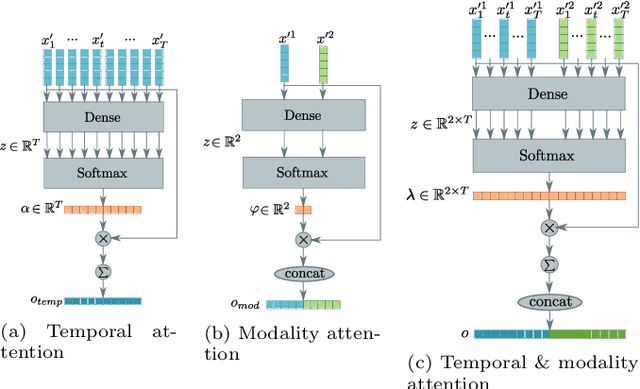
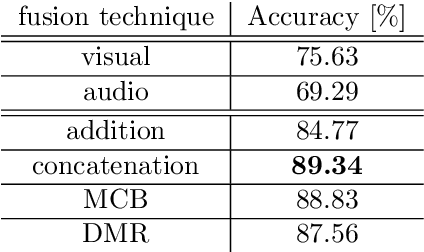
Event classification is inherently sequential and multimodal. Therefore, deep neural models need to dynamically focus on the most relevant time window and/or modality of a video. In this study, we propose the Multi-level Attention Fusion network (MAFnet), an architecture that can dynamically fuse visual and audio information for event recognition. Inspired by prior studies in neuroscience, we couple both modalities at different levels of visual and audio paths. Furthermore, the network dynamically highlights a modality at a given time window relevant to classify events. Experimental results in AVE (Audio-Visual Event), UCF51, and Kinetics-Sounds datasets show that the approach can effectively improve the accuracy in audio-visual event classification. Code is available at: https://github.com/numediart/MAFnet