 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Document Keyphrase Extraction: A Literature Review and the First Dataset
Paper and Code
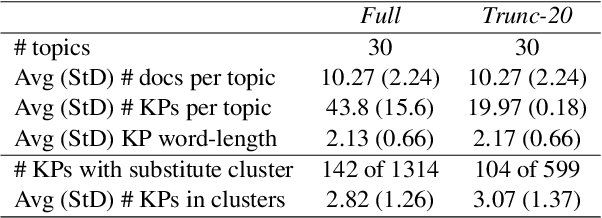
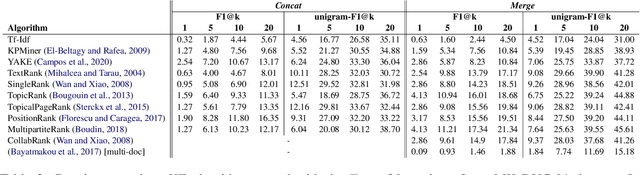
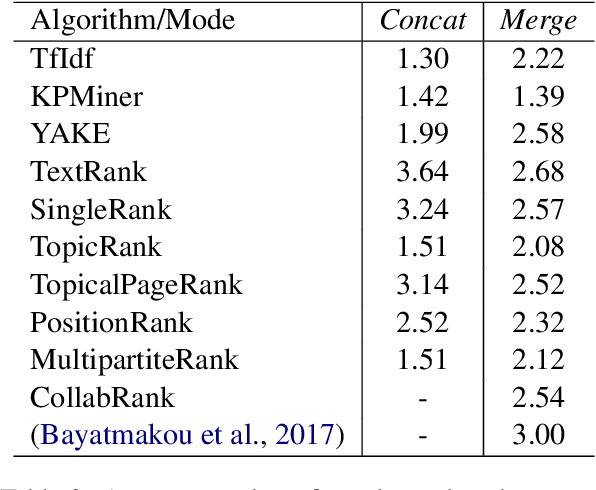
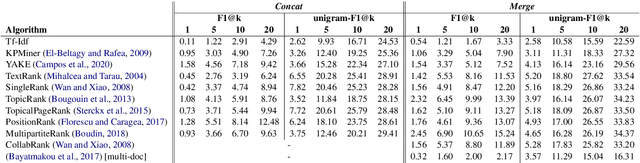
Keyphrase extraction has been comprehensively researched within the single-document setting, with an abundance of methods and a wealth of datasets. In contrast, multi-document keyphrase extraction has been infrequently studied, despite its utility for describing sets of documents, and its use in summarization. Moreover, no dataset existed for multi-document keyphrase extraction, hindering the progress of the task. Recent advances in multi-text processing make the task an even more appealing challenge to pursue. To initiate this pursuit, we present here the first literature review and the first dataset for the task, MK-DUC-01, which can serve as a new benchmark. We test several keyphrase extraction baselines on our data and show their results.