 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMT-PATCHER: Selective and Extendable Knowledge Distillation from Large Language Models for Machine Translation
Paper and Code
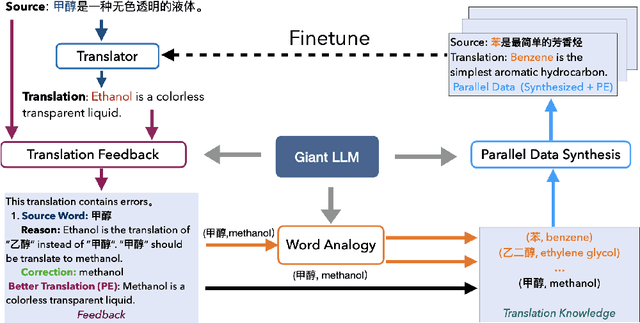
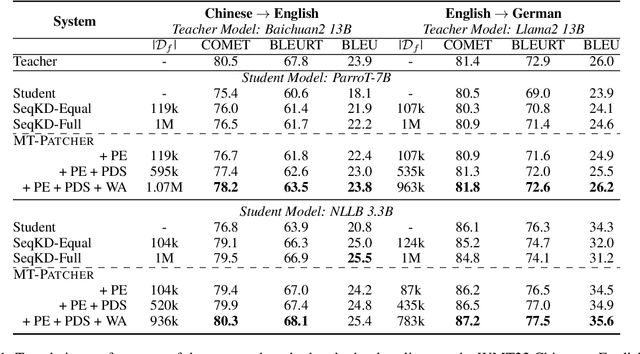
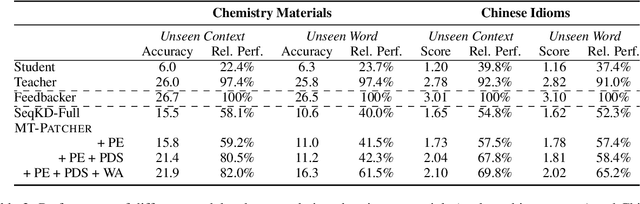
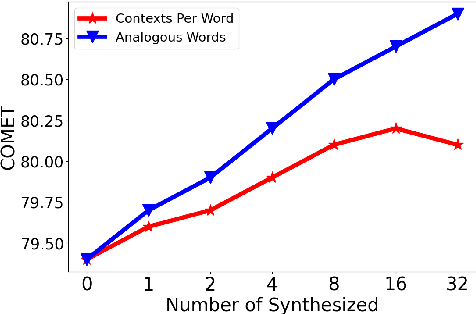
Large Language Models (LLM) have demonstrated their strong ability in the field of machine translation (MT), yet they suffer from high computational cost and latency. Therefore, transferring translation knowledge from giant LLMs to medium-sized machine translation models is a promising research direction. However, traditional knowledge distillation methods do not take the capability of student and teacher models into consideration, therefore repeatedly teaching student models on the knowledge they have learned, and failing to extend to novel contexts and knowledge. In this paper, we propose a framework called MT-Patcher, which transfers knowledge from LLMs to existing MT models in a selective, comprehensive and proactive manner. Considering the current translation ability of student MT models, we only identify and correct their translation errors, instead of distilling the whole translation from the teacher. Leveraging the strong language abilities of LLMs, we instruct LLM teachers to synthesize diverse contexts and anticipate more potential errors for the student. Experiment results on translating both specific language phenomena and general MT benchmarks demonstrate that finetuning the student MT model on about 10% examples can achieve comparable results to the traditional knowledge distillation method, and synthesized potential errors and diverse contexts further improve translation performances on unseen contexts and words.