 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRSN: Multi-Relation Support Network for Video Action Detection
Paper and Code
Apr 24, 2023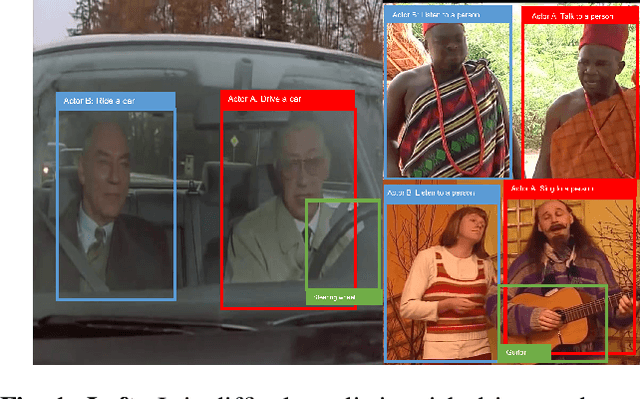
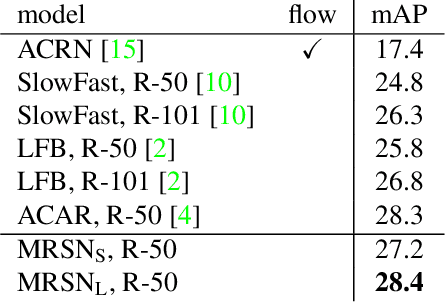
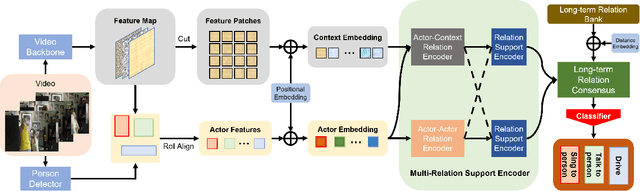
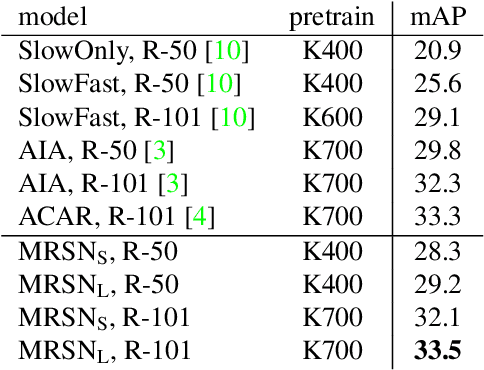
Action detection is a challenging video understanding task, requiring modeling spatio-temporal and interaction relations. Current methods usually model actor-actor and actor-context relations separately, ignoring their complementarity and mutual support. To solve this problem, we propose a novel network called Multi-Relation Support Network (MRSN). In MRSN, Actor-Context Relation Encoder (ACRE) and Actor-Actor Relation Encoder (AARE) model the actor-context and actor-actor relation separately. Then Relation Support Encoder (RSE) computes the supports between the two relations and performs relation-level interactions. Finally, Relation Consensus Module (RCM) enhances two relations with the long-term relations from the Long-term Relation Bank (LRB) and yields a consensus. Our experiments demonstrate that modeling relations separately and performing relation-level interactions can achieve and outperformer state-of-the-art results on two challenging video datasets: AVA and UCF101-24.