 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphosyntactic Tagging with Pre-trained Language Models for Arabic and its Dialects
Paper and Code
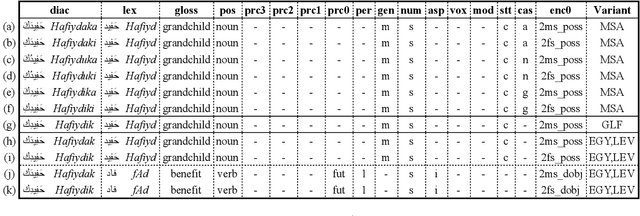
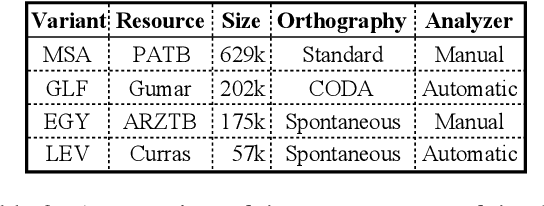
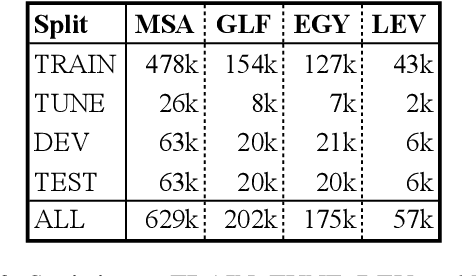
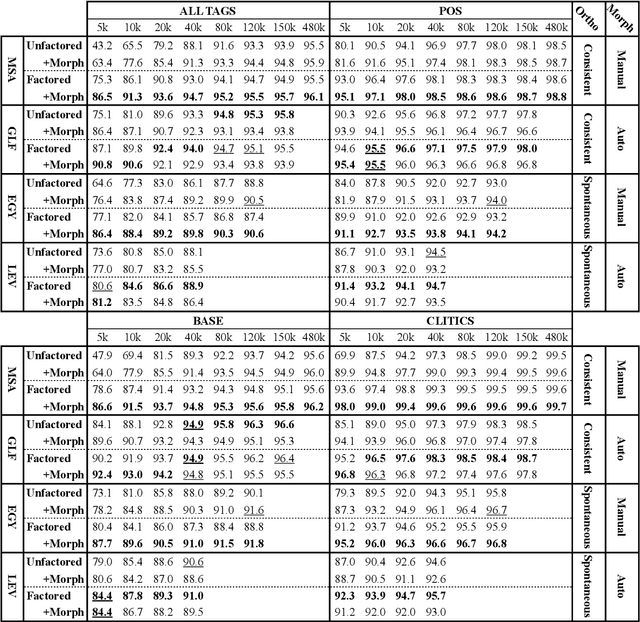
We present state-of-the-art results on morphosyntactic tagging across different varieties of Arabic using fine-tuned pre-trained transformer language models. Our models consistently outperform existing systems in Modern Standard Arabic and all the Arabic dialects we study, achieving 2.6% absolute improvement over the previous state-of-the-art in Modern Standard Arabic, 2.8% in Gulf, 1.6% in Egyptian, and 7.0% in Levantine. We explore different training setups for fine-tuning pre-trained transformer language models, including training data size, the use of external linguistic resources, and the use of annotated data from other dialects in a low-resource scenario. Our results show that strategic fine-tuning using datasets from other high-resource dialects is beneficial for a low-resource dialect. Additionally, we show that high-quality morphological analyzers as external linguistic resources are beneficial especially in low-resource settings.