 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphology Without Borders: Clause-Level Morphological Annotation
Paper and Code

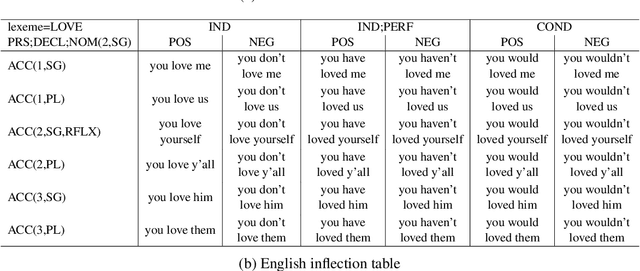


Morphological tasks use large multi-lingual datasets that organize words into inflection tables, which then serve as training and evaluation data for various tasks. However, a closer inspection of these data reveals profound cross-linguistic inconsistencies, that arise from the lack of a clear linguistic and operational definition of what is a word, and that severely impair the universality of the derived tasks. To overcome this deficiency, we propose to view morphology as a clause-level phenomenon, rather than word-level. It is anchored in a fixed yet inclusive set of features homogeneous across languages, that encapsulates all functions realized in a saturated clause. We deliver MightyMorph, a novel dataset for clause-level morphology covering 4 typologically-different languages: English, German, Turkish and Hebrew. We use this dataset to derive 3 clause-level morphological tasks: inflection, reinflection and analysis. Our experiments show that the clause-level tasks are substantially harder than the respective word-level tasks, while having comparable complexity across languages. Furthermore, redefining morphology to the clause-level provides a neat interface with contextualized language models (LMs) and can be used to probe LMs capacity to encode complex morphology. Taken together, this work opens up new horizons in the study of computational morphology, leaving ample space for studying neural morphological modeling cross-linguistically.