 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Human Digitization via Implicit Re-projection Networks
Paper and Code
May 16, 2022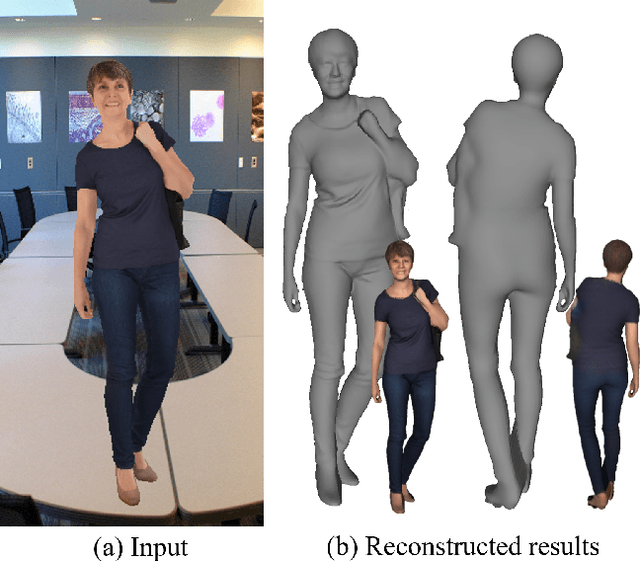
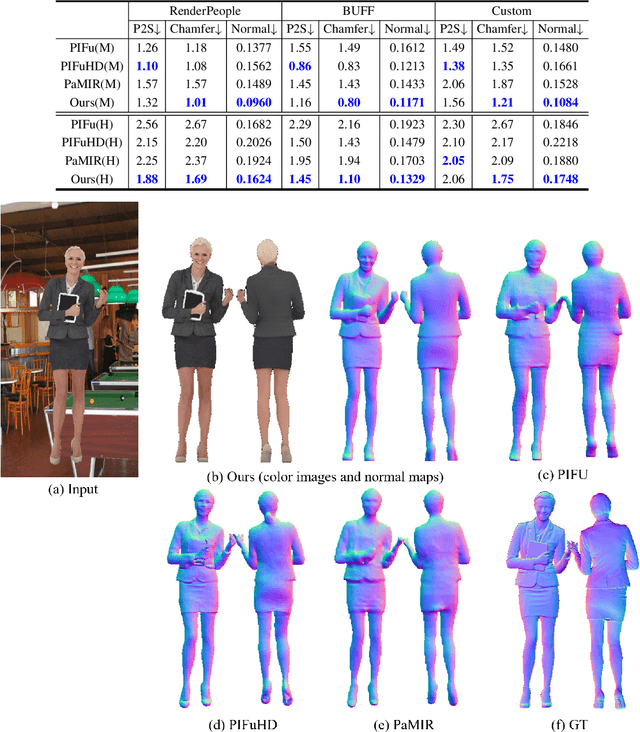
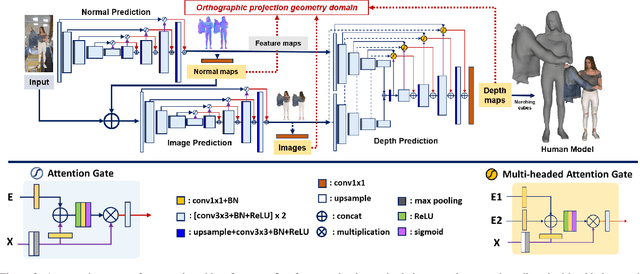
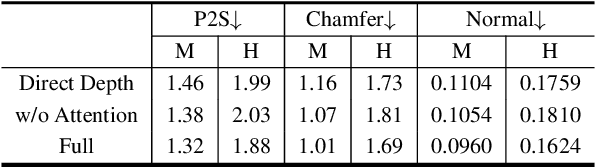
We present an approach to generating 3D human models from images. The key to our framework is that we predict double-sided orthographic depth maps and color images from a single perspective projected image. Our framework consists of three networks. The first network predicts normal maps to recover geometric details such as wrinkles in the clothes and facial regions. The second network predicts shade-removed images for the front and back views by utilizing the predicted normal maps. The last multi-headed network takes both normal maps and shade-free images and predicts depth maps while selectively fusing photometric and geometric information through multi-headed attention gates. Experimental results demonstrate that our method shows visually plausible results and competitive performance in terms of various evaluation metrics over state-of-the-art methods.