 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonge-Kantorovich Fitting With Sobolev Budgets
Paper and Code
Sep 25, 2024
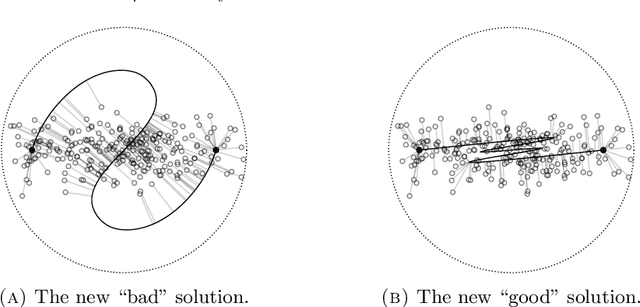
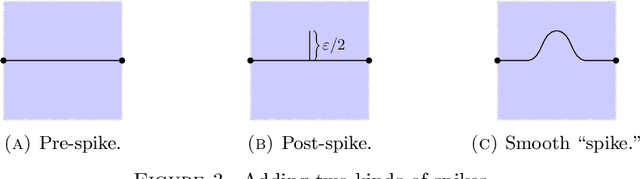

We consider the problem of finding the ``best'' approximation of an $n$-dimensional probability measure $\rho$ using a measure $\nu$ whose support is parametrized by $f : \mathbb{R}^m \to \mathbb{R}^n$ where $m < n$. We quantify the performance of the approximation with the Monge-Kantorovich $p$-cost (also called the Wasserstein $p$-cost) $\mathbb{W}_p^p(\rho, \nu)$, and constrain the complexity of the approximation by bounding the $W^{k,q}$ Sobolev norm of $f$, which acts as a ``budget.'' We may then reformulate the problem as minimizing a functional $\mathscr{J}_p(f)$ under a constraint on the Sobolev budget. We treat general $k \geq 1$ for the Sobolev differentiability order (though $q, m$ are chosen to restrict $W^{k,q}$ to the supercritical regime $k q > m$ to guarantee existence of optimizers). The problem is closely related to (but distinct from) principal curves with length constraints when $m=1, k = 1$ and smoothing splines when $k > 1$. New aspects and challenges arise from the higher order differentiability condition. We study the gradient of $\mathscr{J}_p$, which is given by a vector field along $f$ we call the barycenter field. We use it to construct improvements to a given $f$, which gives a nontrivial (almost) strict monotonicty relation between the functional $\mathscr{J}_p$ and the Sobolev budget. We also provide a natural discretization scheme and establish its consistency. We use this scheme to model a generative learning task; in particular, we demonstrate that adding a constraint like ours as a soft penalty yields substantial improvement in training a GAN to produce images of handwritten digits, with performance competitive with weight-decay.