Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Speech-to-Text Translation for Zero-Shot Cross-Modal Transfer
Paper and Code
Oct 05, 2023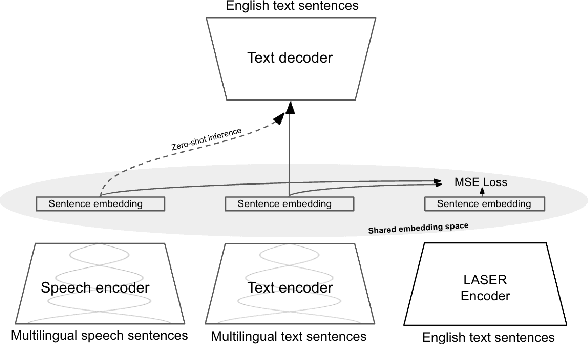
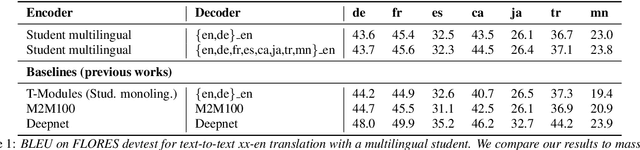

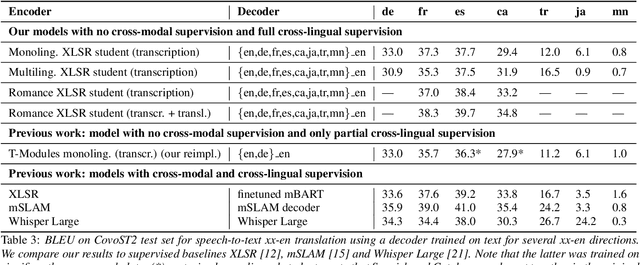
Recent research has shown that independently trained encoders and decoders, combined through a shared fixed-size representation, can achieve competitive performance in speech-to-text translation. In this work, we show that this type of approach can be further improved with multilingual training. We observe significant improvements in zero-shot cross-modal speech translation, even outperforming a supervised approach based on XLSR for several languages.
* Proceedings of Interspeech 2023
View paper on