Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Representations for Weak Disentanglement
Paper and Code
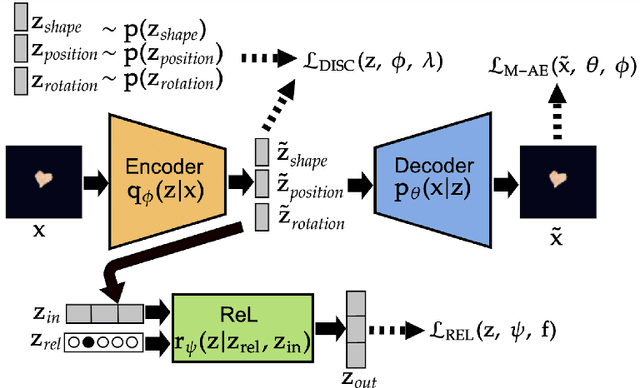
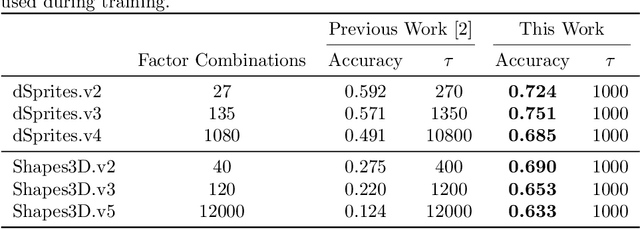

The recently introduced weakly disentangled representations proposed to relax some constraints of the previous definitions of disentanglement, in exchange for more flexibility. However, at the moment, weak disentanglement can only be achieved by increasing the amount of supervision as the number of factors of variations of the data increase. In this paper, we introduce modular representations for weak disentanglement, a novel method that allows to keep the amount of supervised information constant with respect the number of generative factors. The experiments shows that models using modular representations can increase their performance with respect to previous work without the need of additional supervision.
* Accepted at ESANN2022
View paper on