 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModified Actor-Critics
Paper and Code
Jul 02, 2019

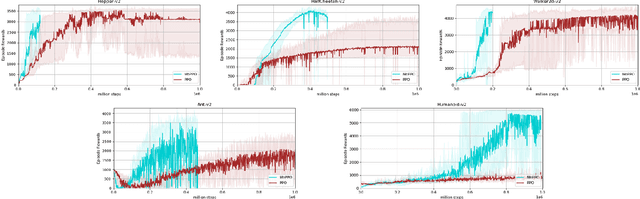

Robot Learning, from a control point of view, often involves continuous actions. In Reinforcement Learning, such actions are usually handled with actor-critic algorithms. They may build on Conservative Policy Iteration (e.g., Trust Region Policy Optimization, TRPO), on policy gradient (e.g., Reinforce), on entropy regularization (e.g., Soft Actor Critic, SAC), among others (e.g., Proximal Policy Optimization, PPO), but in all cases they can be seen as a form of soft policy iteration: they iterate policy evaluation followed by a soft policy improvement step. As so, they often are naturally on-policy. In this paper, we propose to combine (any kind of) soft greediness with Modified Policy Iteration (MPI). The proposed abstract framework applies repeatedly: (i) a partial policy evaluation step that allows off-policy learning and (ii) any soft greedy step. As a proof of concept, we instantiate this framework with the PPO soft greediness. Comparison to the original PPO shows that our algorithm is much more sample efficient. We also show that it is competitive with the state-of-art off-policy algorithm SAC.