 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModerately supervised learning: definition and framework
Paper and Code
Aug 27, 2020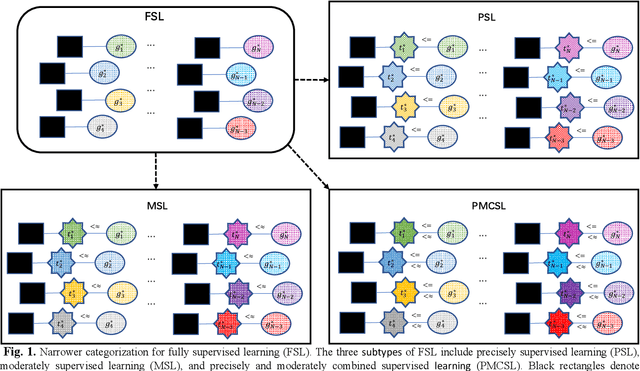

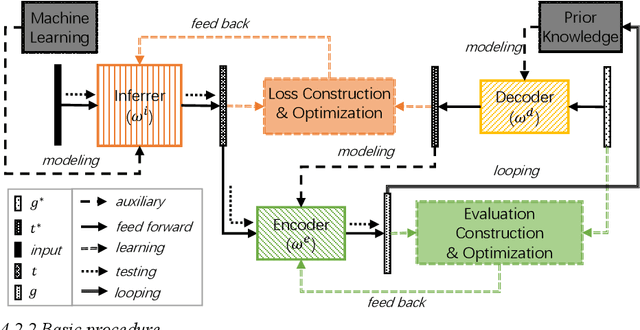
Supervised learning (SL) has achieved remarkable success in numerous artificial intelligence applications. In the current literature, by referring to the properties of the ground-truth labels prepared for a training data set, SL is roughly categorized as fully supervised learning (FSL) and weakly supervised learning (WSL). However, solutions for various FSL tasks have shown that the given ground-truth labels are not always learnable, and the target transformation from the given ground-truth labels to learnable targets can significantly affect the performance of the final FSL solutions. Without considering the properties of the target transformation from the given ground-truth labels to learnable targets, the roughness of the FSL category conceals some details that can be critical to building the optimal solutions for some specific FSL tasks. Thus, it is desirable to reveal these details. This article attempts to achieve this goal by expanding the categorization of FSL and investigating the subtype that plays the central role in FSL. Taking into consideration the properties of the target transformation from the given ground-truth labels to learnable targets, we first categorize FSL into three narrower subtypes. Then, we focus on the subtype moderately supervised learning (MSL). MSL concerns the situation where the given ground-truth labels are ideal, but due to the simplicity in annotation of the given ground-truth labels, careful designs are required to transform the given ground-truth labels into learnable targets. From the perspectives of definition and framework, we comprehensively illustrate MSL to reveal what details are concealed by the roughness of the FSL category. Finally, discussions on the revealed details suggest that MSL should be given more attention.