 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModels and Datasets for Cross-Lingual Summarisation
Paper and Code

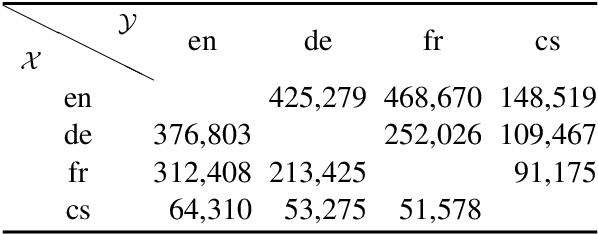
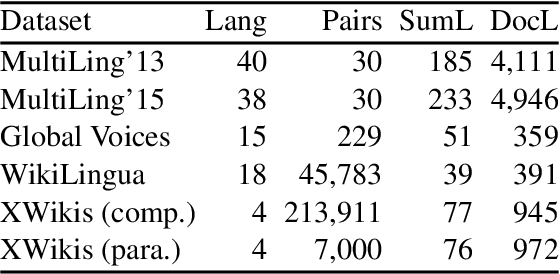

We present a cross-lingual summarisation corpus with long documents in a source language associated with multi-sentence summaries in a target language. The corpus covers twelve language pairs and directions for four European languages, namely Czech, English, French and German, and the methodology for its creation can be applied to several other languages. We derive cross-lingual document-summary instances from Wikipedia by combining lead paragraphs and articles' bodies from language aligned Wikipedia titles. We analyse the proposed cross-lingual summarisation task with automatic metrics and validate it with a human study. To illustrate the utility of our dataset we report experiments with multi-lingual pre-trained models in supervised, zero- and few-shot, and out-of-domain scenarios.