 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling of Speech-dependent Own Voice Transfer Characteristics for Hearables with In-ear Microphones
Paper and Code
Oct 10, 2023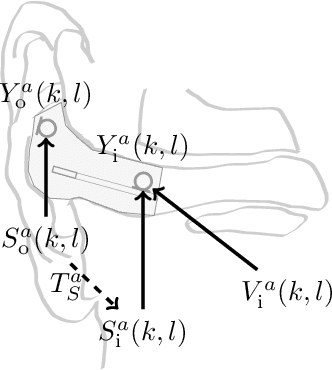



Hearables often contain an in-ear microphone, which may be used to capture the own voice of its user. However, due to ear canal occlusion the in-ear microphone mostly records body-conducted speech, which suffers from band-limitation effects and is subject to amplification of low frequency content. These transfer characteristics are assumed to vary both based on speech content and between individual talkers. It is desirable to have an accurate model of the own voice transfer characteristics between hearable microphones. Such a model can be used, e.g., to simulate a large amount of in-ear recordings to train supervised learning-based algorithms aiming at compensating own voice transfer characteristics. In this paper we propose a speech-dependent system identification model based on phoneme recognition. Using recordings from a prototype hearable, the modeling accuracy is evaluated in terms of technical measures. We investigate robustness of transfer characteristic models to utterance or talker mismatch. Simulation results show that using the proposed speech-dependent model is preferable for simulating in-ear recordings compared to a speech-independent model. The proposed model is able to generalize better to new utterances than an adaptive filtering-based model. Additionally, we find that talker-averaged models generalize better to different talkers than individual models.