Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Drug-Disease Relations with Linguistic and Knowledge Graph Constraints
Paper and Code
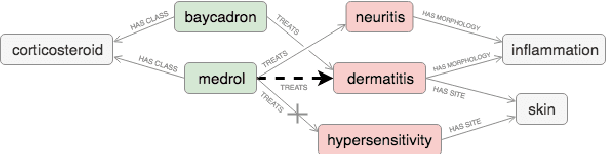
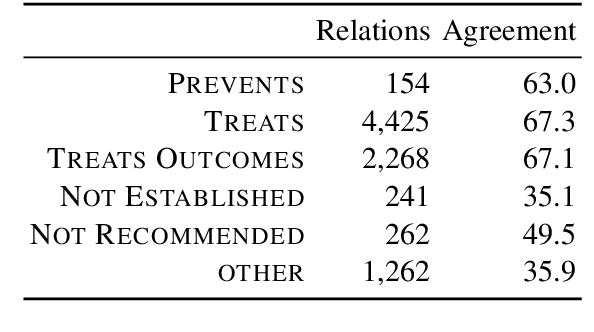
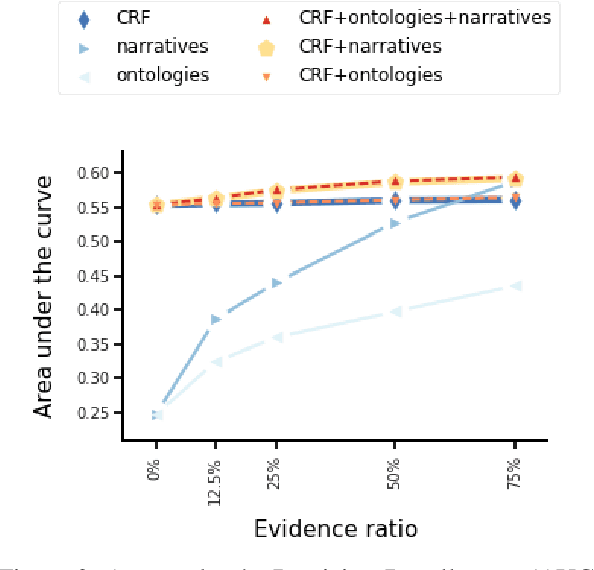
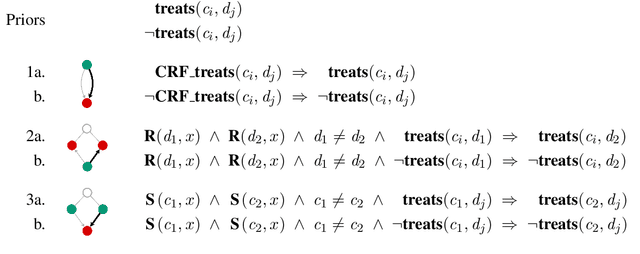
FDA drug labels are rich sources of information about drugs and drug-disease relations, but their complexity makes them challenging texts to analyze in isolation. To overcome this, we situate these labels in two health knowledge graphs: one built from precise structured information about drugs and diseases, and another built entirely from a database of clinical narrative texts using simple heuristic methods. We show that Probabilistic Soft Logic models defined over these graphs are superior to text-only and relation-only variants, and that the clinical narratives graph delivers exceptional results with little manual effort. Finally, we release a new dataset of drug labels with annotations for five distinct drug-disease relations.
View paper on