 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Dependent Structure for Utterances in ASR Evaluation
Paper and Code
Sep 07, 2022
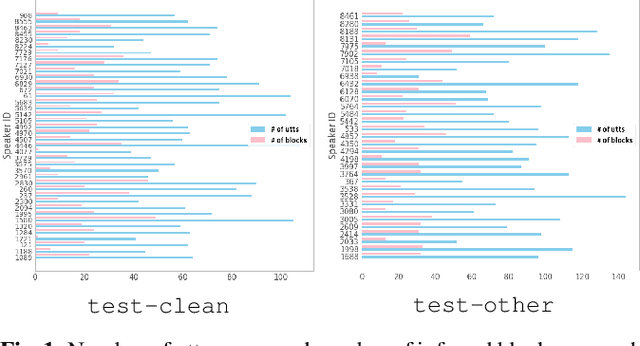
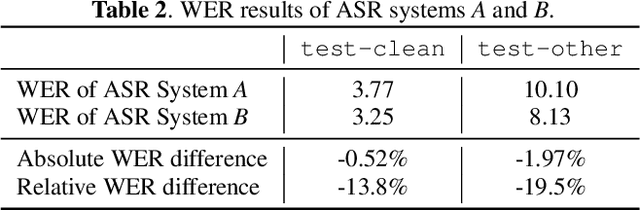
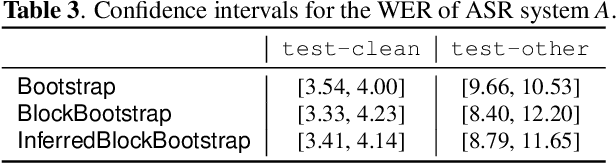
The bootstrap resampling method has been popular for performing significance analysis on word error rate (WER) in automatic speech recognition (ASR) evaluations. To deal with the issue of dependent speech data, the blockwise bootstrap approach is also proposed that by dividing utterances into uncorrelated blocks, it resamples these blocks instead of original data. However, it is always nontrivial to uncover the dependent structure among utterances, which could lead to subjective findings in statistical testing. In this paper, we present graphical lasso based methods to explicitly model such dependency and estimate the independent blocks of utterances in a rigorous way. Then the blockwise bootstrap is applied on top of the inferred blocks. We show that the resulting variance estimator for WER is consistent under mild conditions. We also demonstrate the validity of proposed approach on LibriSpeech data.