 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Explainability in Deep Learning Based Natural Language Processing
Paper and Code
Jun 14, 2021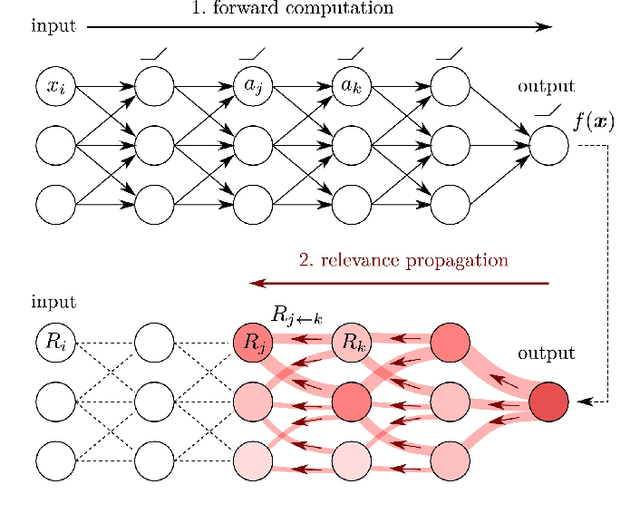

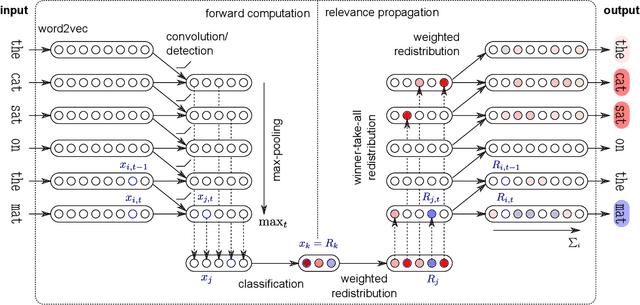

Machine learning (ML) model explainability has received growing attention, especially in the area related to model risk and regulations. In this paper, we reviewed and compared some popular ML model explainability methodologies, especially those related to Natural Language Processing (NLP) models. We then applied one of the NLP explainability methods Layer-wise Relevance Propagation (LRP) to a NLP classification model. We used the LRP method to derive a relevance score for each word in an instance, which is a local explainability. The relevance scores are then aggregated together to achieve global variable importance of the model. Through the case study, we also demonstrated how to apply the local explainability method to false positive and false negative instances to discover the weakness of a NLP model. These analysis can help us to understand NLP models better and reduce the risk due to the black-box nature of NLP models. We also identified some common issues due to the special natures of NLP models and discussed how explainability analysis can act as a control to detect these issues after the model has been trained.