 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Compression for Resource-Constrained Mobile Robots
Paper and Code
Jul 20, 2022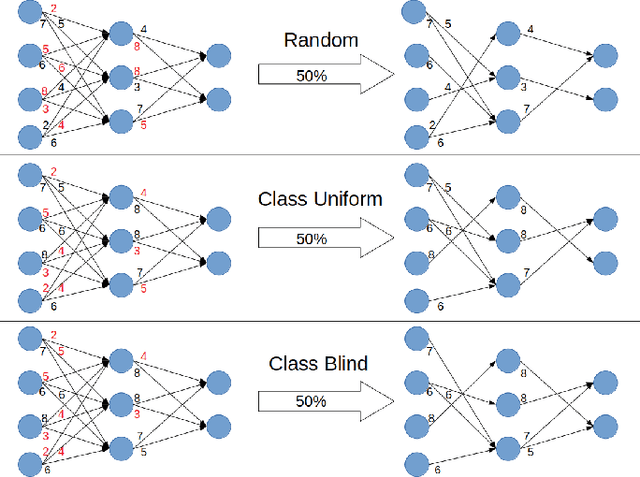



The number of mobile robots with constrained computing resources that need to execute complex machine learning models has been increasing during the past decade. Commonly, these robots rely on edge infrastructure accessible over wireless communication to execute heavy computational complex tasks. However, the edge might become unavailable and, consequently, oblige the execution of the tasks on the robot. This work focuses on making it possible to execute the tasks on the robots by reducing the complexity and the total number of parameters of pre-trained computer vision models. This is achieved by using model compression techniques such as Pruning and Knowledge Distillation. These compression techniques have strong theoretical and practical foundations, but their combined usage has not been widely explored in the literature. Therefore, this work especially focuses on investigating the effects of combining these two compression techniques. The results of this work reveal that up to 90% of the total number of parameters of a computer vision model can be removed without any considerable reduction in the model's accuracy.