 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Complexity of Program Phases
Paper and Code
Oct 05, 2023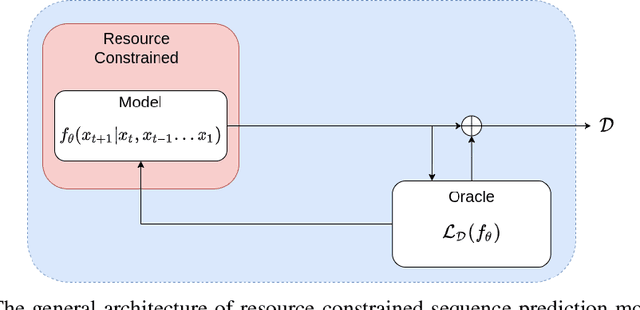
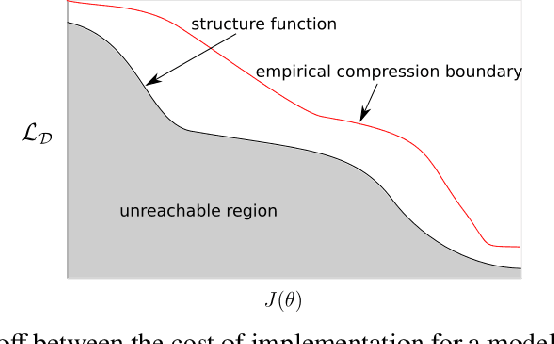

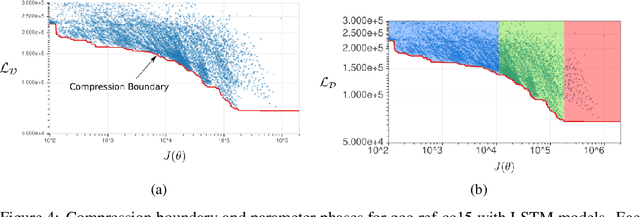
In resource limited computing systems, sequence prediction models must operate under tight constraints. Various models are available that cater to prediction under these conditions that in some way focus on reducing the cost of implementation. These resource constrained sequence prediction models, in practice, exhibit a fundamental tradeoff between the cost of implementation and the quality of its predictions. This fundamental tradeoff seems to be largely unexplored for models for different tasks. Here we formulate the necessary theory and an associated empirical procedure to explore this tradeoff space for a particular family of machine learning models such as deep neural networks. We anticipate that the knowledge of the behavior of this tradeoff may be beneficial in understanding the theoretical and practical limits of creation and deployment of models for resource constrained tasks.