 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile Keyboard Input Decoding with Finite-State Transducers
Paper and Code
Apr 13, 2017

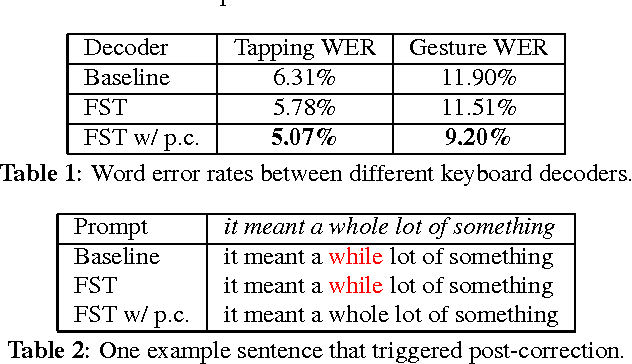
We propose a finite-state transducer (FST) representation for the models used to decode keyboard inputs on mobile devices. Drawing from learnings from the field of speech recognition, we describe a decoding framework that can satisfy the strict memory and latency constraints of keyboard input. We extend this framework to support functionalities typically not present in speech recognition, such as literal decoding, autocorrections, word completions, and next word predictions. We describe the general framework of what we call for short the keyboard "FST decoder" as well as the implementation details that are new compared to a speech FST decoder. We demonstrate that the FST decoder enables new UX features such as post-corrections. Finally, we sketch how this decoder can support advanced features such as personalization and contextualization.