 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMNet-Sim: A Multi-layered Semantic Similarity Network to Evaluate Sentence Similarity
Paper and Code
Nov 09, 2021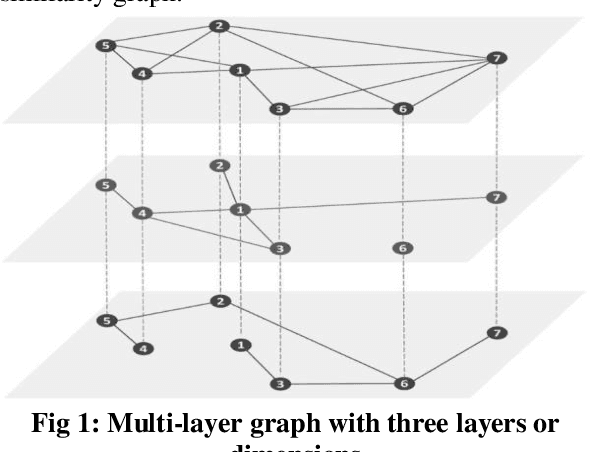
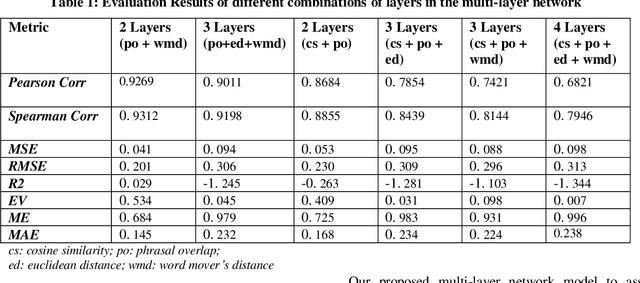
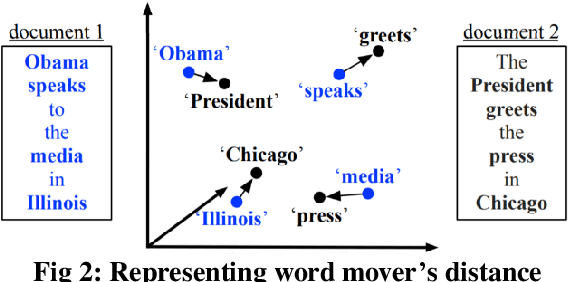
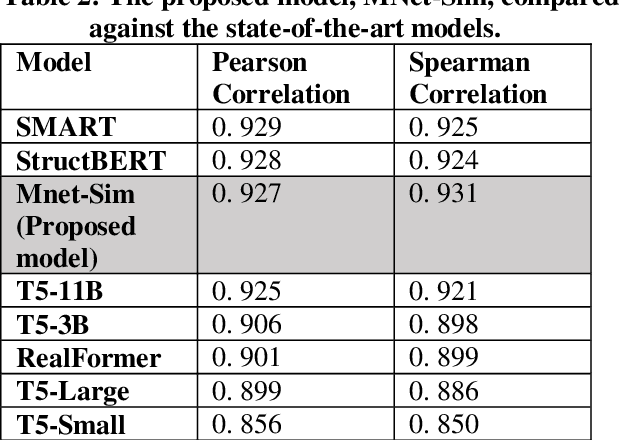
Similarity is a comparative-subjective measure that varies with the domain within which it is considered. In several NLP applications such as document classification, pattern recognition, chatbot question-answering, sentiment analysis, etc., identifying an accurate similarity score for sentence pairs has become a crucial area of research. In the existing models that assess similarity, the limitation of effectively computing this similarity based on contextual comparisons, the localization due to the centering theory, and the lack of non-semantic textual comparisons have proven to be drawbacks. Hence, this paper presents a multi-layered semantic similarity network model built upon multiple similarity measures that render an overall sentence similarity score based on the principles of Network Science, neighboring weighted relational edges, and a proposed extended node similarity computation formula. The proposed multi-layered network model was evaluated and tested against established state-of-the-art models and is shown to have demonstrated better performance scores in assessing sentence similarity.