Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLT-LE: predicting drug-target binding affinity with multi-task residual neural networks
Paper and Code

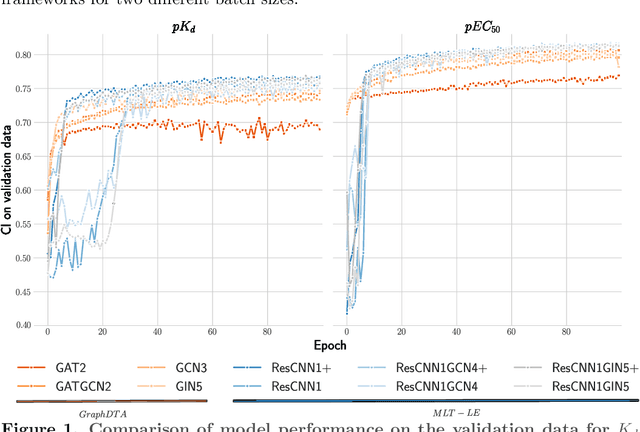
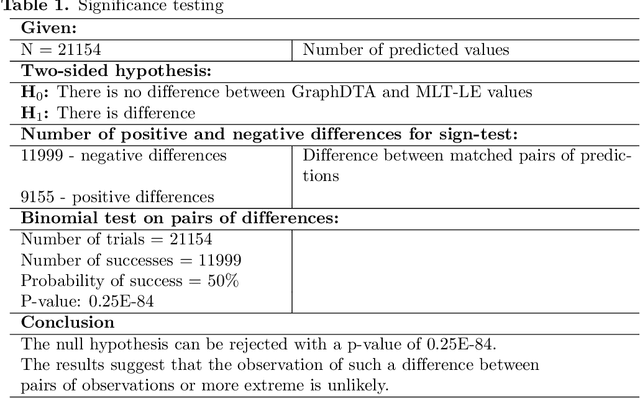
Assessing drug-target affinity is a critical step in the drug discovery and development process, but to obtain such data experimentally is both time consuming and expensive. For this reason, computational methods for predicting binding strength are being widely developed. However, these methods typically use a single-task approach for prediction, thus ignoring the additional information that can be extracted from the data and used to drive the learning process. Thereafter in this work, we present a multi-task approach for binding strength prediction. Our results suggest that these prediction can indeed benefit from a multi-task learning approach, by utilizing added information from related tasks and multi-task induced regularization.
* Associated data, pre-trained models, and source code are publicly
available at https://github.com/VeaLi/MLT-LE
View paper on