 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture Matrix Completion
Paper and Code
Aug 02, 2018
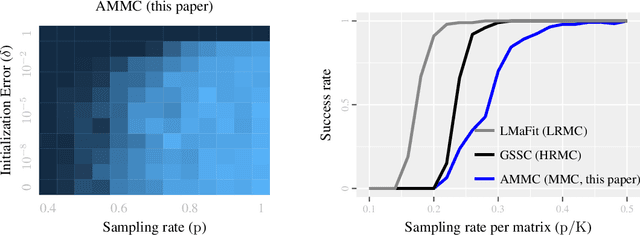

Completing a data matrix X has become an ubiquitous problem in modern data science, with applications in recommender systems, computer vision, and networks inference, to name a few. One typical assumption is that X is low-rank. A more general model assumes that each column of X corresponds to one of several low-rank matrices. This paper generalizes these models to what we call mixture matrix completion (MMC): the case where each entry of X corresponds to one of several low-rank matrices. MMC is a more accurate model for recommender systems, and brings more flexibility to other completion and clustering problems. We make four fundamental contributions about this new model. First, we show that MMC is theoretically possible (well-posed). Second, we give its precise information-theoretic identifiability conditions. Third, we derive the sample complexity of MMC. Finally, we give a practical algorithm for MMC with performance comparable to the state-of-the-art for simpler related problems, both on synthetic and real data.