 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixing syntagmatic and paradigmatic information for concept detection
Paper and Code

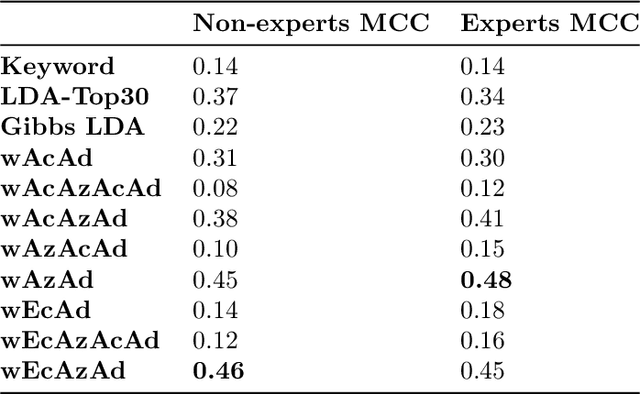


In the last decades, philosophers have begun using empirical data for conceptual analysis, but corpus-based conceptual analysis has so far failed to develop, in part because of the absence of reliable methods to automatically detect concepts in textual data. Previous attempts have shown that topic models can constitute efficient concept detection heuristics, but while they leverage the syntagmatic relations in a corpus, they fail to exploit paradigmatic relations, and thus probably fail to model concepts accurately. In this article, we show that using a topic model that models concepts on a space of word embeddings (Hu and Tsujii, 2016) can lead to significant increases in concept detection performance, as well as enable the target concept to be expressed in more flexible ways using word vectors.