 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixAugment & Mixup: Augmentation Methods for Facial Expression Recognition
Paper and Code
May 09, 2022
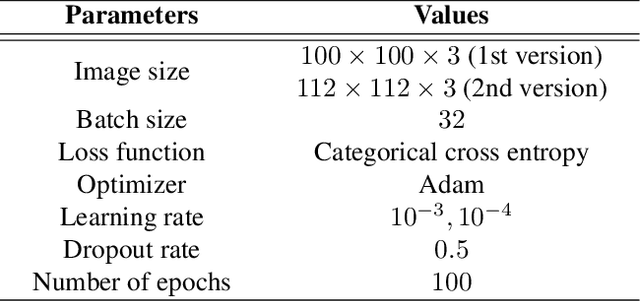

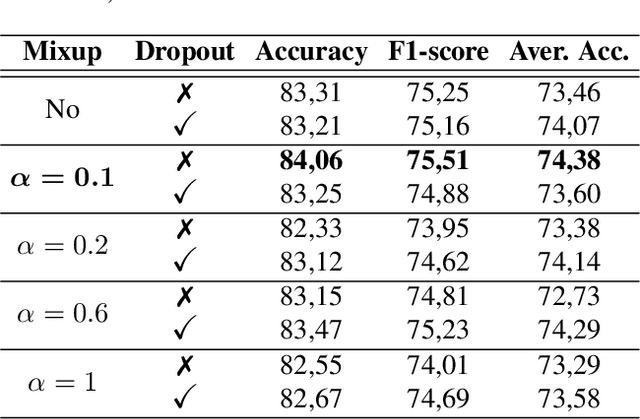
Automatic Facial Expression Recognition (FER) has attracted increasing attention in the last 20 years since facial expressions play a central role in human communication. Most FER methodologies utilize Deep Neural Networks (DNNs) that are powerful tools when it comes to data analysis. However, despite their power, these networks are prone to overfitting, as they often tend to memorize the training data. What is more, there are not currently a lot of in-the-wild (i.e. in unconstrained environment) large databases for FER. To alleviate this issue, a number of data augmentation techniques have been proposed. Data augmentation is a way to increase the diversity of available data by applying constrained transformations on the original data. One such technique, which has positively contributed to various classification tasks, is Mixup. According to this, a DNN is trained on convex combinations of pairs of examples and their corresponding labels. In this paper, we examine the effectiveness of Mixup for in-the-wild FER in which data have large variations in head poses, illumination conditions, backgrounds and contexts. We then propose a new data augmentation strategy which is based on Mixup, called MixAugment. According to this, the network is trained concurrently on a combination of virtual examples and real examples; all these examples contribute to the overall loss function. We conduct an extensive experimental study that proves the effectiveness of MixAugment over Mixup and various state-of-the-art methods. We further investigate the combination of dropout with Mixup and MixAugment, as well as the combination of other data augmentation techniques with MixAugment.