 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating the Stability-Plasticity Dilemma in Adaptive Train Scheduling with Curriculum-Driven Continual DQN Expansion
Paper and Code
Aug 19, 2024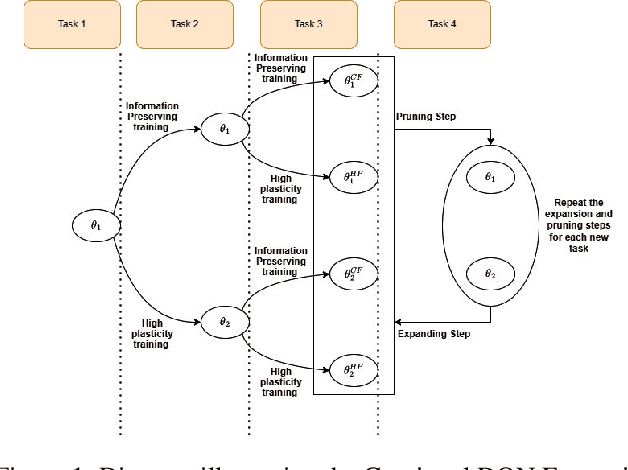


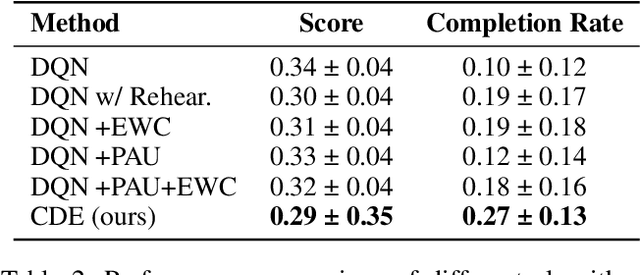
A continual learning agent builds on previous experiences to develop increasingly complex behaviors by adapting to non-stationary and dynamic environments while preserving previously acquired knowledge. However, scaling these systems presents significant challenges, particularly in balancing the preservation of previous policies with the adaptation of new ones to current environments. This balance, known as the stability-plasticity dilemma, is especially pronounced in complex multi-agent domains such as the train scheduling problem, where environmental and agent behaviors are constantly changing, and the search space is vast. In this work, we propose addressing these challenges in the train scheduling problem using curriculum learning. We design a curriculum with adjacent skills that build on each other to improve generalization performance. Introducing a curriculum with distinct tasks introduces non-stationarity, which we address by proposing a new algorithm: Continual Deep Q-Network (DQN) Expansion (CDE). Our approach dynamically generates and adjusts Q-function subspaces to handle environmental changes and task requirements. CDE mitigates catastrophic forgetting through EWC while ensuring high plasticity using adaptive rational activation functions. Experimental results demonstrate significant improvements in learning efficiency and adaptability compared to RL baselines and other adapted methods for continual learning, highlighting the potential of our method in managing the stability-plasticity dilemma in the adaptive train scheduling setting.