 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Bias in Set Selection with Noisy Protected Attributes
Paper and Code
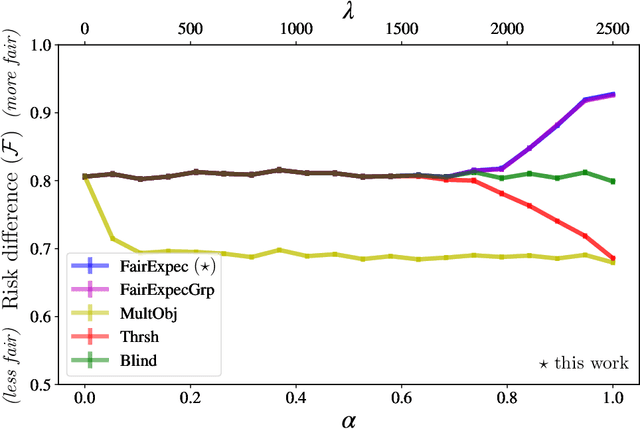
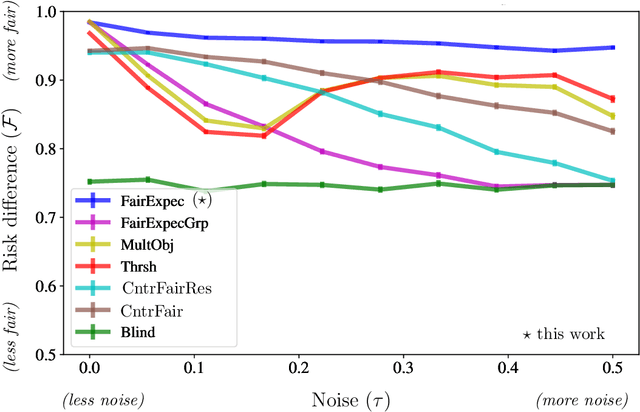
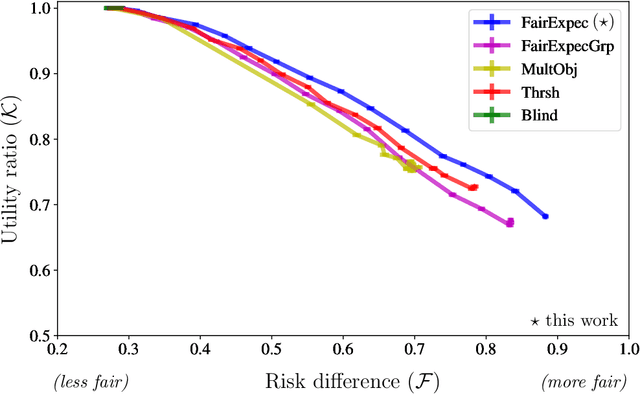

Subset selection algorithms are ubiquitous in AI-driven applications, including, online recruiting portals and image search engines, so it is imperative that these tools are not discriminatory on the basis of protected attributes such as gender or race. Currently, fair subset selection algorithms assume that the protected attributes are known as part of the dataset. However, attributes may be noisy due to errors during data collection or if they are imputed (as is often the case in real-world settings). While a wide body of work addresses the effect of noise on the performance of machine learning algorithms, its effect on fairness remains largely unexamined. We find that in the presence of noisy protected attributes, in attempting to increase fairness without considering noise, one can, in fact, decrease the fairness of the result! Towards addressing this, we consider an existing noise model in which there is probabilistic information about the protected attributes (e.g.,[19, 32, 56, 44]), and ask is fair selection is possible under noisy conditions? We formulate a ``denoised'' selection problem which functions for a large class of fairness metrics; given the desired fairness goal, the solution to the denoised problem violates the goal by at most a small multiplicative amount with high probability. Although the denoised problem turns out to be NP-hard, we give a linear-programming based approximation algorithm for it. We empirically evaluate our approach on both synthetic and real-world datasets. Our empirical results show that this approach can produce subsets which significantly improve the fairness metrics despite the presence of noisy protected attributes, and, compared to prior noise-oblivious approaches, has better Pareto-tradeoffs between utility and fairness.