 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Adversarial Attacks by Distributing Different Copies to Different Users
Paper and Code
Nov 30, 2021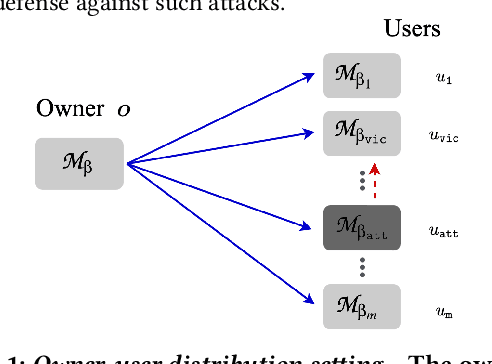

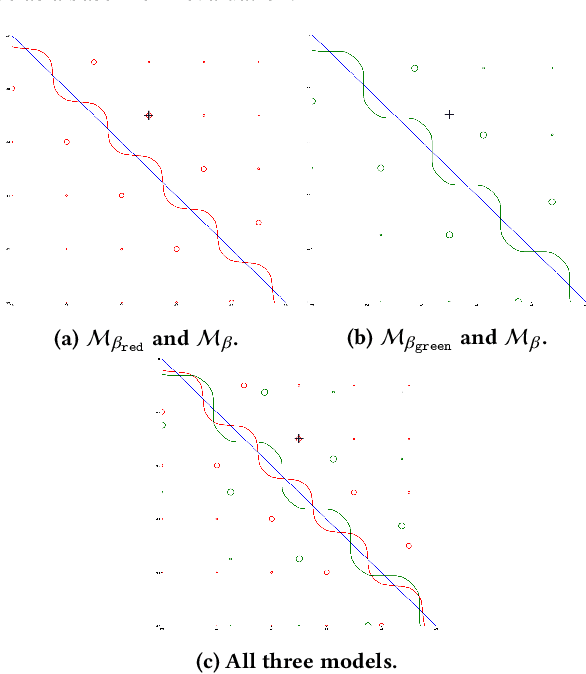
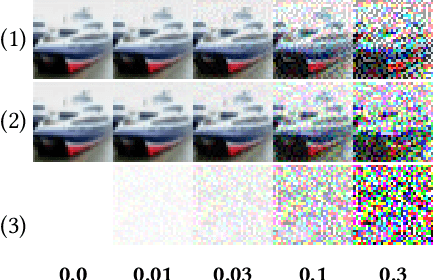
Machine learning models are vulnerable to adversarial attacks. In this paper, we consider the scenario where a model is to be distributed to multiple users, among which a malicious user attempts to attack another user. The malicious user probes its copy of the model to search for adversarial samples and then presents the found samples to the victim's model in order to replicate the attack. We point out that by distributing different copies of the model to different users, we can mitigate the attack such that adversarial samples found on one copy would not work on another copy. We first observed that training a model with different randomness indeed mitigates such replication to certain degree. However, there is no guarantee and retraining is computationally expensive. Next, we propose a flexible parameter rewriting method that directly modifies the model's parameters. This method does not require additional training and is able to induce different sets of adversarial samples in different copies in a more controllable manner. Experimentation studies show that our approach can significantly mitigate the attacks while retaining high classification accuracy. From this study, we believe that there are many further directions worth exploring.