 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIT-10M: A Large Scale Parallel Corpus of Multilingual Image Translation
Paper and Code
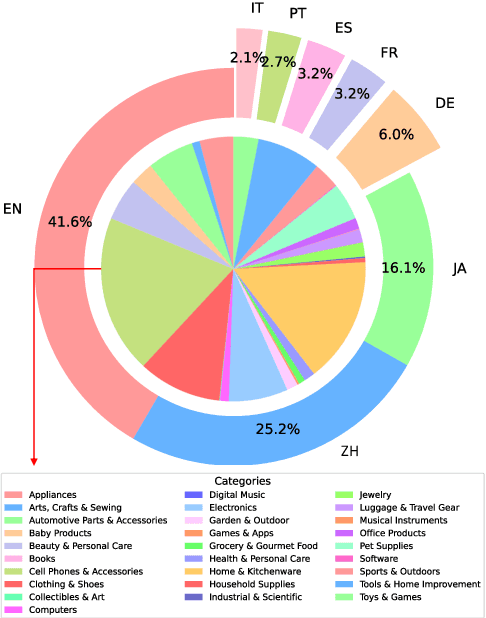
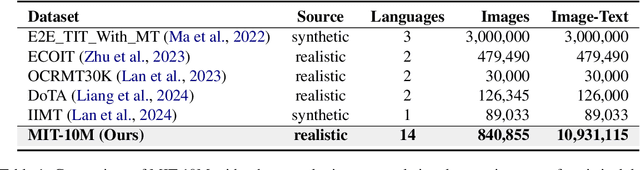
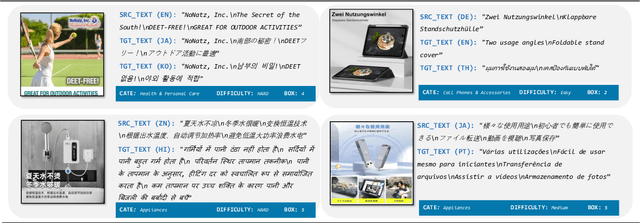
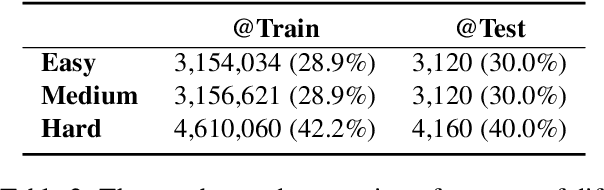
Image Translation (IT) holds immense potential across diverse domains, enabling the translation of textual content within images into various languages. However, existing datasets often suffer from limitations in scale, diversity, and quality, hindering the development and evaluation of IT models. To address this issue, we introduce MIT-10M, a large-scale parallel corpus of multilingual image translation with over 10M image-text pairs derived from real-world data, which has undergone extensive data cleaning and multilingual translation validation. It contains 840K images in three sizes, 28 categories, tasks with three levels of difficulty and 14 languages image-text pairs, which is a considerable improvement on existing datasets. We conduct extensive experiments to evaluate and train models on MIT-10M. The experimental results clearly indicate that our dataset has higher adaptability when it comes to evaluating the performance of the models in tackling challenging and complex image translation tasks in the real world. Moreover, the performance of the model fine-tuned with MIT-10M has tripled compared to the baseline model, further confirming its superiority.