 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMISAR: A Multimodal Instructional System with Augmented Reality
Paper and Code
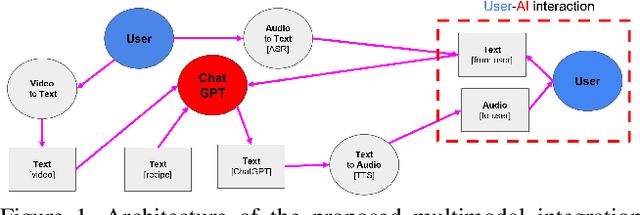
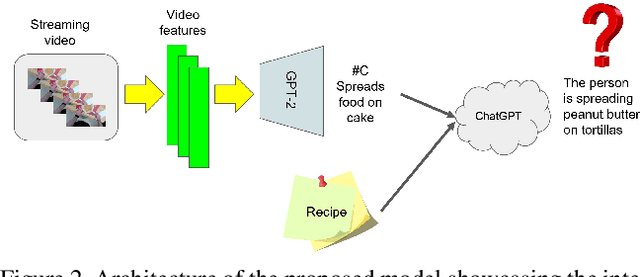
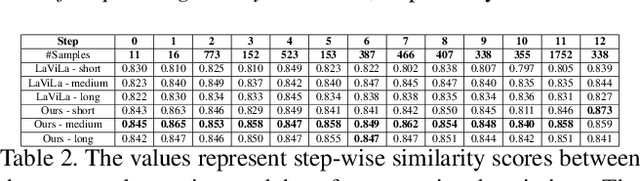
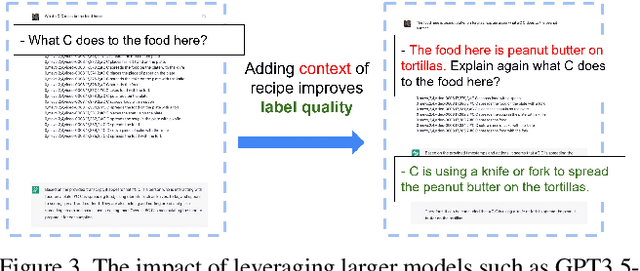
Augmented reality (AR) requires the seamless integration of visual, auditory, and linguistic channels for optimized human-computer interaction. While auditory and visual inputs facilitate real-time and contextual user guidance, the potential of large language models (LLMs) in this landscape remains largely untapped. Our study introduces an innovative method harnessing LLMs to assimilate information from visual, auditory, and contextual modalities. Focusing on the unique challenge of task performance quantification in AR, we utilize egocentric video, speech, and context analysis. The integration of LLMs facilitates enhanced state estimation, marking a step towards more adaptive AR systems. Code, dataset, and demo will be available at https://github.com/nguyennm1024/misar.