 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Associated Text and Images with Dual-Wing Harmoniums
Paper and Code
Jul 04, 2012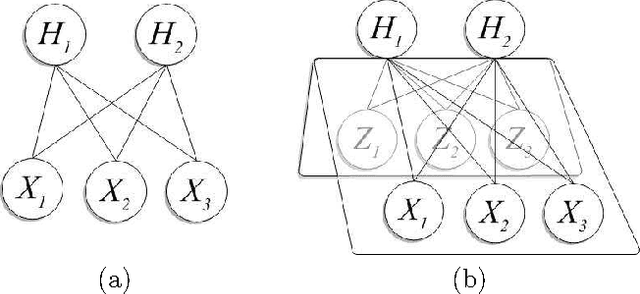

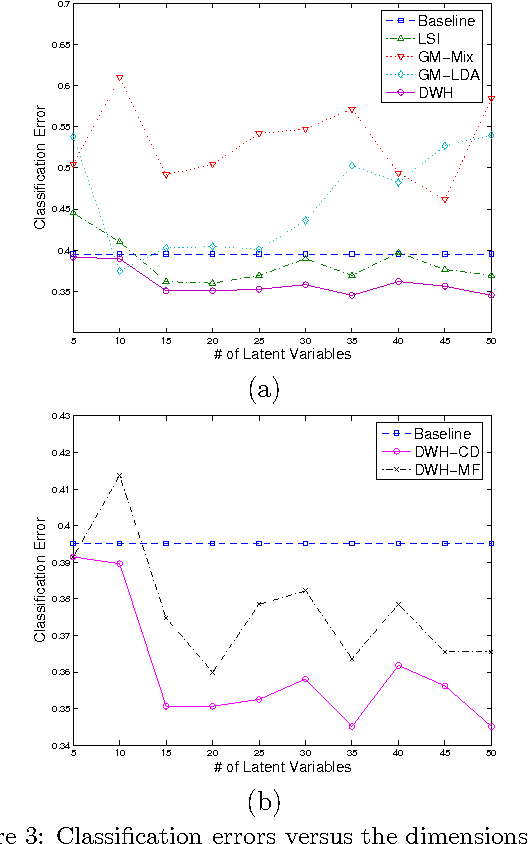
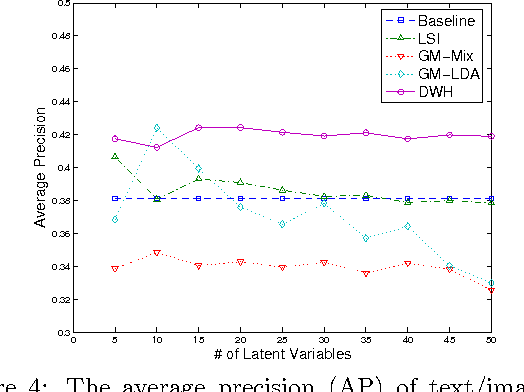
We propose a multi-wing harmonium model for mining multimedia data that extends and improves on earlier models based on two-layer random fields, which capture bidirectional dependencies between hidden topic aspects and observed inputs. This model can be viewed as an undirected counterpart of the two-layer directed models such as LDA for similar tasks, but bears significant difference in inference/learning cost tradeoffs, latent topic representations, and topic mixing mechanisms. In particular, our model facilitates efficient inference and robust topic mixing, and potentially provides high flexibilities in modeling the latent topic spaces. A contrastive divergence and a variational algorithm are derived for learning. We specialized our model to a dual-wing harmonium for captioned images, incorporating a multivariate Poisson for word-counts and a multivariate Gaussian for color histogram. We present empirical results on the applications of this model to classification, retrieval and image annotation on news video collections, and we report an extensive comparison with various extant models.