 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimum Probability Flow Learning
Paper and Code

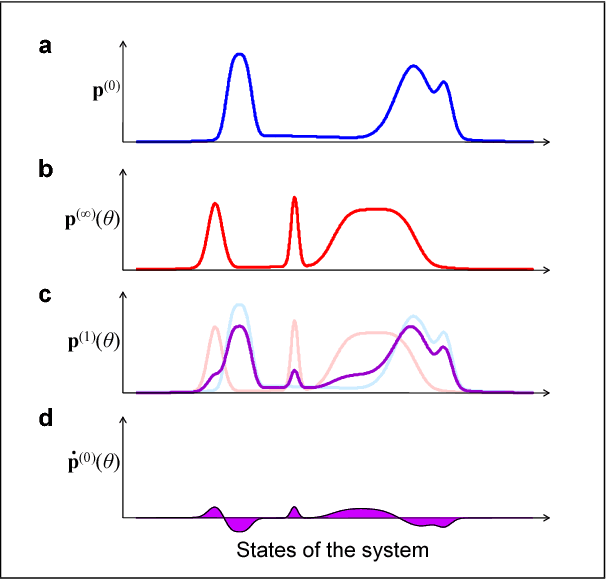
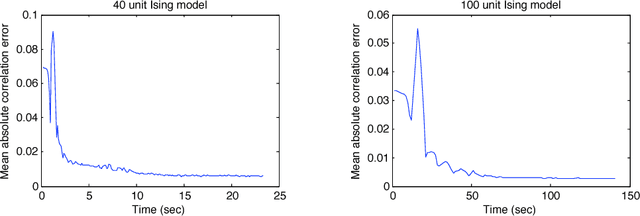
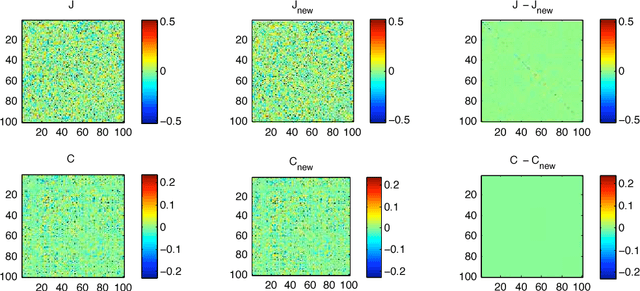
Fitting probabilistic models to data is often difficult, due to the general intractability of the partition function and its derivatives. Here we propose a new parameter estimation technique that does not require computing an intractable normalization factor or sampling from the equilibrium distribution of the model. This is achieved by establishing dynamics that would transform the observed data distribution into the model distribution, and then setting as the objective the minimization of the KL divergence between the data distribution and the distribution produced by running the dynamics for an infinitesimal time. Score matching, minimum velocity learning, and certain forms of contrastive divergence are shown to be special cases of this learning technique. We demonstrate parameter estimation in Ising models, deep belief networks and an independent component analysis model of natural scenes. In the Ising model case, current state of the art techniques are outperformed by at least an order of magnitude in learning time, with lower error in recovered coupling parameters.