 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimally Supervised Written-to-Spoken Text Normalization
Paper and Code
Sep 21, 2016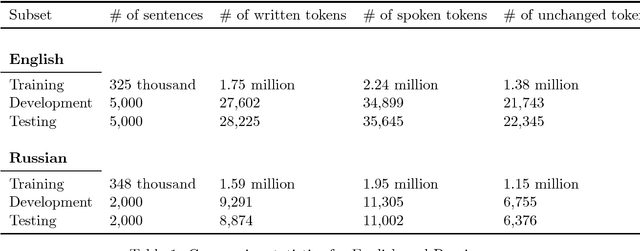
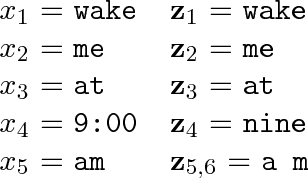

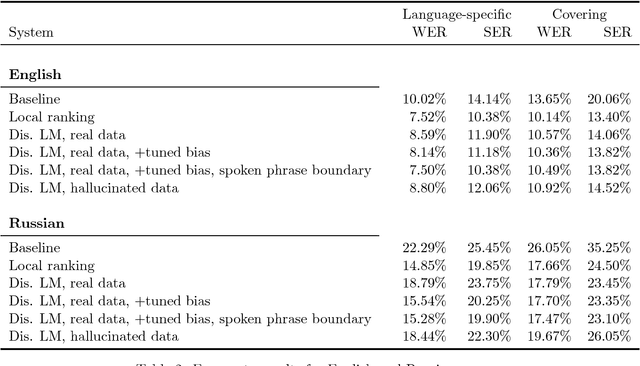
In speech-applications such as text-to-speech (TTS) or automatic speech recognition (ASR), \emph{text normalization} refers to the task of converting from a \emph{written} representation into a representation of how the text is to be \emph{spoken}. In all real-world speech applications, the text normalization engine is developed---in large part---by hand. For example, a hand-built grammar may be used to enumerate the possible ways of saying a given token in a given language, and a statistical model used to select the most appropriate pronunciation in context. In this study we examine the tradeoffs associated with using more or less language-specific domain knowledge in a text normalization engine. In the most data-rich scenario, we have access to a carefully constructed hand-built normalization grammar that for any given token will produce a set of all possible verbalizations for that token. We also assume a corpus of aligned written-spoken utterances, from which we can train a ranking model that selects the appropriate verbalization for the given context. As a substitute for the carefully constructed grammar, we also consider a scenario with a language-universal normalization \emph{covering grammar}, where the developer merely needs to provide a set of lexical items particular to the language. As a substitute for the aligned corpus, we also consider a scenario where one only has the spoken side, and the corresponding written side is "hallucinated" by composing the spoken side with the inverted normalization grammar. We investigate the accuracy of a text normalization engine under each of these scenarios. We report the results of experiments on English and Russian.