 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric Distribution to Vector: Constructing Data Representation via Broad-Scale Discrepancies
Paper and Code
Oct 02, 2022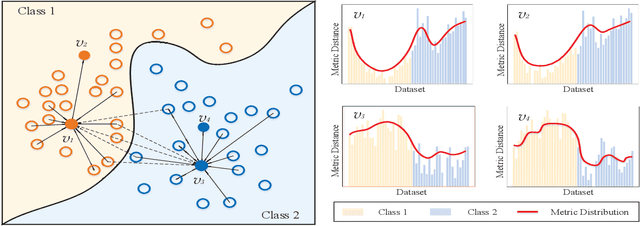
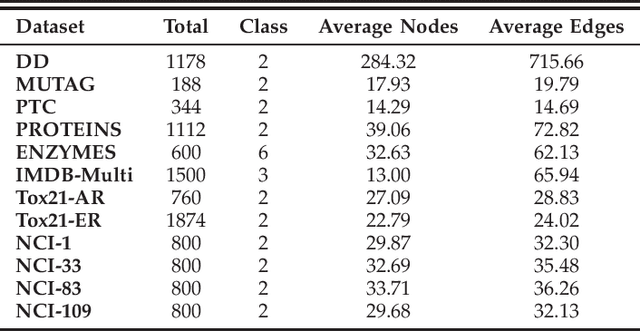
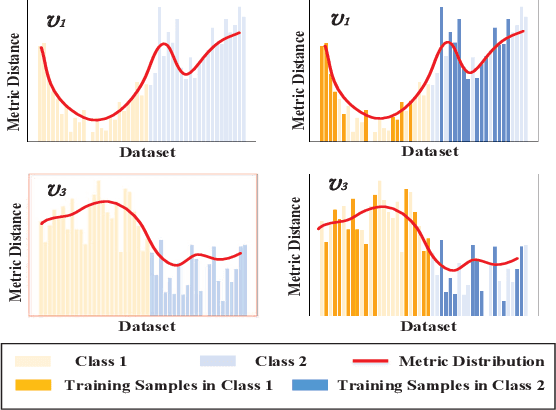

Graph embedding provides a feasible methodology to conduct pattern classification for graph-structured data by mapping each data into the vectorial space. Various pioneering works are essentially coding method that concentrates on a vectorial representation about the inner properties of a graph in terms of the topological constitution, node attributions, link relations, etc. However, the classification for each targeted data is a qualitative issue based on understanding the overall discrepancies within the dataset scale. From the statistical point of view, these discrepancies manifest a metric distribution over the dataset scale if the distance metric is adopted to measure the pairwise similarity or dissimilarity. Therefore, we present a novel embedding strategy named $\mathbf{MetricDistribution2vec}$ to extract such distribution characteristics into the vectorial representation for each data. We demonstrate the application and effectiveness of our representation method in the supervised prediction tasks on extensive real-world structural graph datasets. The results have gained some unexpected increases compared with a surge of baselines on all the datasets, even if we take the lightweight models as classifiers. Moreover, the proposed methods also conducted experiments in Few-Shot classification scenarios, and the results still show attractive discrimination in rare training samples based inference.