 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-TTS: Meta-Learning for Few-Shot Speaker Adaptive Text-to-Speech
Paper and Code
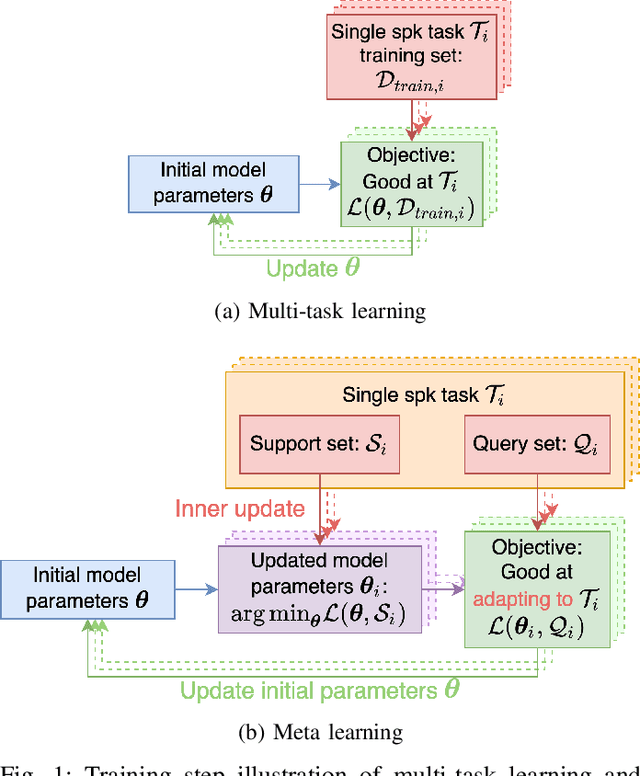
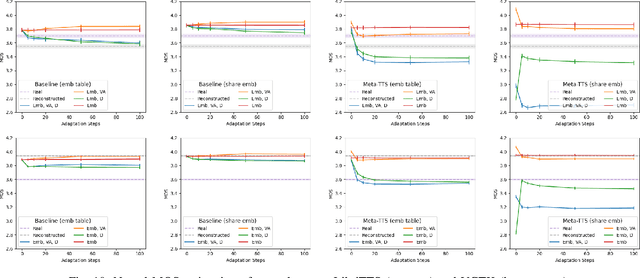
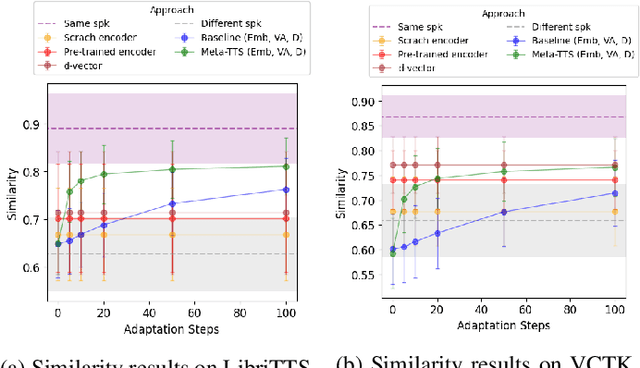
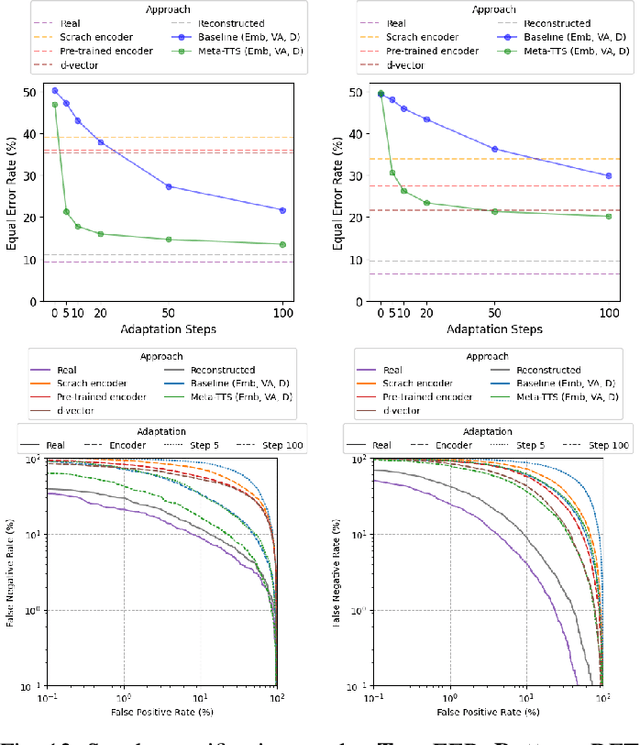
Personalizing a speech synthesis system is a highly desired application, where the system can generate speech with the user's voice with rare enrolled recordings. There are two main approaches to build such a system in recent works: speaker adaptation and speaker encoding. On the one hand, speaker adaptation methods fine-tune a trained multi-speaker text-to-speech (TTS) model with few enrolled samples. However, they require at least thousands of fine-tuning steps for high-quality adaptation, making it hard to apply on devices. On the other hand, speaker encoding methods encode enrollment utterances into a speaker embedding. The trained TTS model can synthesize the user's speech conditioned on the corresponding speaker embedding. Nevertheless, the speaker encoder suffers from the generalization gap between the seen and unseen speakers. In this paper, we propose applying a meta-learning algorithm to the speaker adaptation method. More specifically, we use Model Agnostic Meta-Learning (MAML) as the training algorithm of a multi-speaker TTS model, which aims to find a great meta-initialization to adapt the model to any few-shot speaker adaptation tasks quickly. Therefore, we can also adapt the meta-trained TTS model to unseen speakers efficiently. Our experiments compare the proposed method (Meta-TTS) with two baselines: a speaker adaptation method baseline and a speaker encoding method baseline. The evaluation results show that Meta-TTS can synthesize high speaker-similarity speech from few enrollment samples with fewer adaptation steps than the speaker adaptation baseline and outperforms the speaker encoding baseline under the same training scheme. When the speaker encoder of the baseline is pre-trained with extra 8371 speakers of data, Meta-TTS can still outperform the baseline on LibriTTS dataset and achieve comparable results on VCTK dataset.