 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Transfer Learning for Low-Resource Abstractive Summarization
Paper and Code
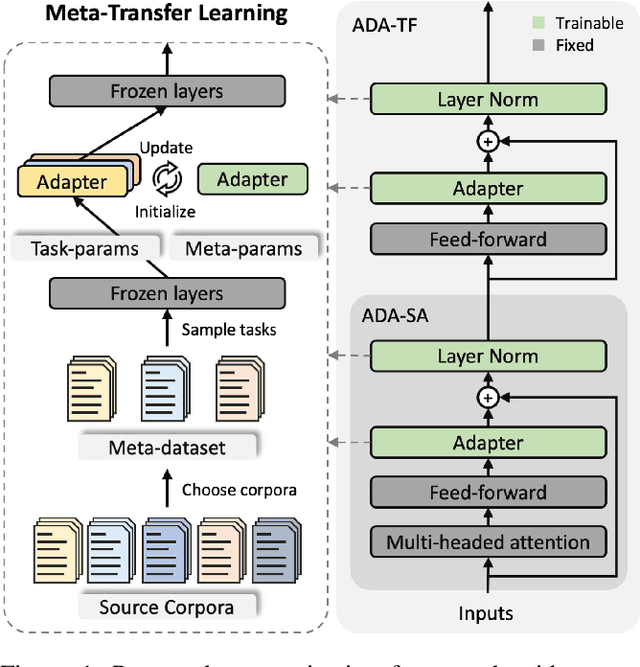
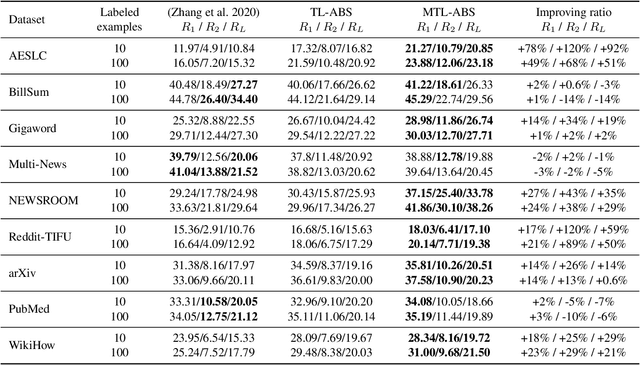
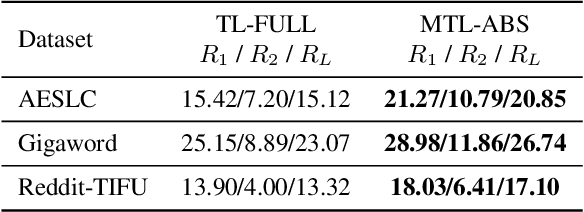
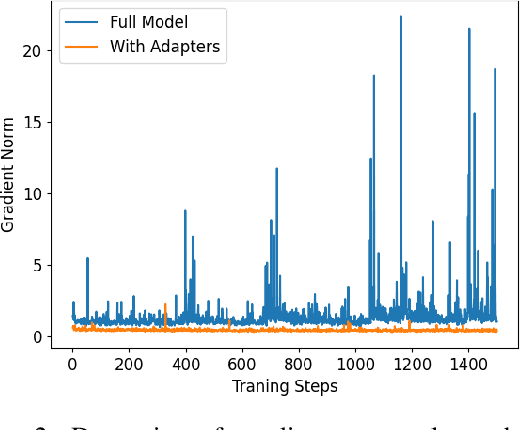
Neural abstractive summarization has been studied in many pieces of literature and achieves great success with the aid of large corpora. However, when encountering novel tasks, one may not always benefit from transfer learning due to the domain shifting problem, and overfitting could happen without adequate labeled examples. Furthermore, the annotations of abstractive summarization are costly, which often demand domain knowledge to ensure the ground-truth quality. Thus, there are growing appeals for Low-Resource Abstractive Summarization, which aims to leverage past experience to improve the performance with limited labeled examples of target corpus. In this paper, we propose to utilize two knowledge-rich sources to tackle this problem, which are large pre-trained models and diverse existing corpora. The former can provide the primary ability to tackle summarization tasks; the latter can help discover common syntactic or semantic information to improve the generalization ability. We conduct extensive experiments on various summarization corpora with different writing styles and forms. The results demonstrate that our approach achieves the state-of-the-art on 6 corpora in low-resource scenarios, with only 0.7% of trainable parameters compared to previous work.