 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Efficient Continual Learning for Neural Text Classification
Paper and Code
Mar 09, 2022
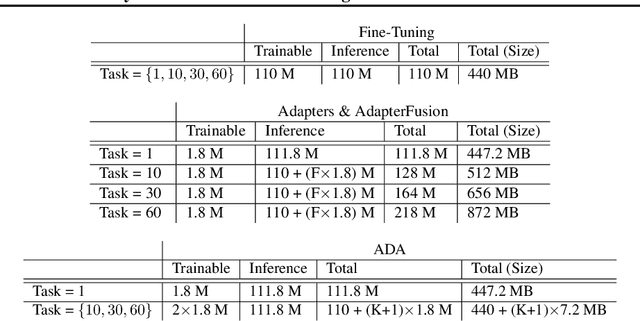
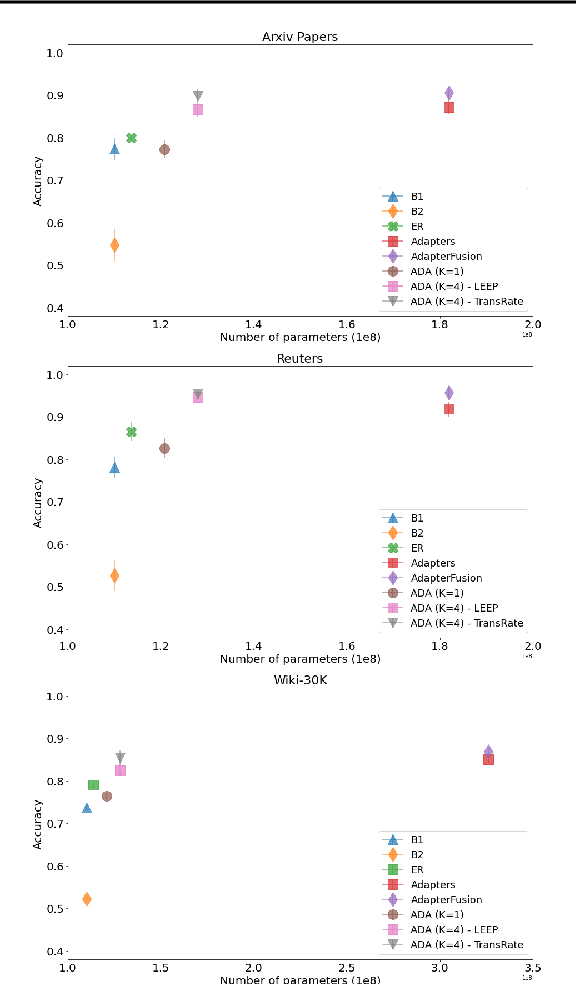

Learning text classifiers based on pre-trained language models has become the standard practice in natural language processing applications. Unfortunately, training large neural language models, such as transformers, from scratch is very costly and requires a vast amount of training data, which might not be available in the application domain of interest. Moreover, in many real-world scenarios, classes are uncovered as more data is seen, calling for class-incremental modelling approaches. In this work we devise a method to perform text classification using pre-trained models on a sequence of classification tasks provided in sequence. We formalize the problem as a continual learning problem where the algorithm learns new tasks without performance degradation on the previous ones and without re-training the model from scratch. We empirically demonstrate that our method requires significantly less model parameters compared to other state of the art methods and that it is significantly faster at inference time. The tight control on the number of model parameters, and so the memory, is not only improving efficiency. It is making possible the usage of the algorithm in real-world applications where deploying a solution with a constantly increasing memory consumption is just unrealistic. While our method suffers little forgetting, it retains a predictive performance on-par with state of the art but less memory efficient methods.